|
|
Modelos de Regressão Não LinearFundamentos e Aplicações em R |
Estimação em modelos não lineares
1 Estimação passo a passo
#-----------------------------------------------------------------------
# Definições da sessão.
library(bbmle)
library(rootSolve)#-----------------------------------------------------------------------
# Exemplo passo a passo de estimação via método Gauss-Newton minimizando
# a SQR.
# Dados artificiais.
y <- matrix(c(0.1, 0.4, 0.6, 0.9))
x <- matrix(c(0.2, 0.5, 0.7, 1.8))
plot(y ~ x, type = "o")
# Especificação do modelo
# Y|x ~ Gaussiana(\mu(x), \sigma)
# \mu(x) = \eta(x, \theta) = 1 - \exp(-x^\theta)
# Função objetivo
# RSS(\theta; x, y) = \sum_{i=1}^{n} [y_i-f(x_i, theta)]^2
# é equivalente a maximizar a verossimilhança.
# Derivada da função em relação a theta.
D(expression(1 - exp(-x^theta)), "theta")
# f(theta, x).
f0 <- function(x, theta) {
1 - exp(-x^theta)
}
# f'(theta, x).
f1 <- function(x, theta) {
exp(-x^theta) * (x^theta * log(x))
}
# Funções que retornam strings das funções quando avaliadas.
f0c <- function(x, theta) {
theta <- formatC(theta, digits = 4, format = "f")
as.matrix(paste("1-exp(-", x, "^", theta, ")", sep = ""))
}
f1c <- function(x, theta) {
theta <- formatC(theta, digits = 4, format = "f")
as.matrix(paste("exp(-", x, "^", theta, ")*(", x, "^", theta,
"*log(", x, "))", sep = ""))
}
#-----------------------------------------------------------------------
# Aplicando o algortimo Gauss-Newton passo a passo.
t0 <- 1.3 # (0) valor inicial
cbind(f0c(x, t0), f0(x, t0)) # (1) valores preditos
F0 <- f1(x, t0)
cbind(f1c(x, t0), F0) # (2) gradiente
r0 <- y - f0(x, t0)
r0 # (3) resíduos
t1 <- t0 + solve(t(F0) %*% F0) %*% t(F0) %*% r0
t1 # (4) atualiza theta
t0 <- c(t1) # fazer de (1) à (5) até convergência.
t1
#-----------------------------------------------------------------------
# Visualiando o ajuste.
plot(y ~ x)
with(list(theta = t0), curve(1 - exp(-x^theta), col = 2, add = TRUE))
#-----------------------------------------------------------------------
# Quadro de partição de soma de quadrados.
sqtot <- sum(y^2)
sqtcm <- sum((y - mean(y))^2)
sqres <- sum((y - f0(x, t0))^2)
sqreg <- sqtot - sqres
data.frame(GL = c(reg = 1, res = 3),
SQ = c(sqreg, sqres),
QM = c(sqreg/1, sqres/3),
F = c((sqreg/1)/(sqres/3), NA))
#-----------------------------------------------------------------------
# Obtendo estimativa da variância resídual.
s2 <- sum((y - f0(x, t0))^2)/(nrow(x) - 1)
s2
#-----------------------------------------------------------------------
# Obtendo erro-padrão da estimativa.
# simplificado (OLS)
sqrt(solve(t(F0) %*% F0) * s2)
# geral (OLS, WLS, GLS)
sdt <- sqrt(solve(t(F0) %*% solve(diag(s2, nrow(x))) %*% F0))
sdt
#-----------------------------------------------------------------------
# Intervalo de confiança assintótico para estimativa.
t0 + c(-1, 1) * qt(0.975, df = 3) * c(sdt)2 Método Gauss-Newton
#-----------------------------------------------------------------------
# Programando (de forma didática) o algortimo Gauss-Newton.
# 1) Obter f(x, \theta_0).
# 2) Obter F(x, \theta_0) =
# \frac{\partial f(x, \theta)}{\partial\theta^\top}\bigg|_{\theta = \theta_0}
# Dados simulados do modelo Michaelis-Menten.
x <- 1:10
set.seed(111)
y <- 10 * x/(3 + x) + rnorm(x, 0, 0.3)
plot(y ~ x)
# Função deriv3(): derivadas analíticas.
# 1) f em theta.
# 2) f' em theta --> "gradient" (n x p).
# 3) f'' em theta --> "hessian" (n x p x p).
d3 <- deriv3(expr = ~A * x/(V + x),
namevec = c("A", "V"),
function.arg = function(x, A, V) {
NULL
})
class(d3)
d3(x, A = 10, V = 3)
theta0 <- c(7, 5) # Valores iniciais para A e V.
sqr0 <- crossprod(y) # Soma de quadrados total.
maxiter <- 50 # Número máximo de iterações.
i <- 1 # Inicia contador de iterações.
tol <- 1e-8 # Diferença tolerada.
dif <- 2 * tol # Inicializa a diferença entre iterações.
while(i <= maxiter & dif > tol){
# Avalia as funções em theta_i.
at_theta <- d3(x, A = theta0[1], V = theta0[2])
f_pred <- c(at_theta) # Preditos.
f_grad <- attr(at_theta, "gradient") # Gradiente.
res <- (y - f_pred) # Resíduos.
sqr1 <- crossprod(res) # SQ de resíduos.
dif <- abs(sqr0-sqr1) # Diferença em SQRes.
theta1 <- theta0 + # Atualiza theta.
crossprod(solve(crossprod(f_grad)), crossprod(f_grad, res))
# solve(t(f_grad) %*% f_grad) %*% t(f_grad) %*% res
# Exibe resultados.
cat(paste(formatC(c(sqr1, theta0), digits = 6, format = "f"),
collapse = "\t"), "\n")
theta0 <- c(theta1)
sqr0 <- sqr1 # Atualiza variáveis.
i <- i + 1 # Incrementa contador
}
theta0
#-----------------------------------------------------------------------
# Conferindo com a nls().
n0 <- nls(y ~ A * x/(V + x),
start = c(A = 7, V = 5),
trace = TRUE)
coef(n0)
#-----------------------------------------------------------------------
# Quadro de somas de quadrados.
# Modelo não linear vs modelo nulo.
anova(n0, lm(y ~ 1))[2:1, ]
#-----------------------------------------------------------------------
# Coeficiente de determinação.
cor(y, fitted(n0))^2
#-----------------------------------------------------------------------
# Matriz de covariância das estimativas.
f_grad
solve(t(f_grad) %*% f_grad) * (deviance(n0)/df.residual(n0))
vcov(n0) # Covariância.
cov2cor(vcov(n0)) # Correlação.3 Tipos de falha de convergência
#-----------------------------------------------------------------------
# Mensagens de erro durante convergência com a nls().
# 1) Matriz de gradiente singular (devido A = 0).
n0 <- nls(y ~ A * x/(V + x),
start = c(A = 0, V = 5),
trace = TRUE)
theta0 <- c(0, 5)
at_theta <- d3(x, A = theta0[1], V = theta0[2])
f_pred <- c(at_theta)
f_grad <- attr(at_theta, "gradient")
f_grad
crossprod(f_grad)
solve(crossprod(f_grad))
# 2) Indeterminações na avaliação das derivadas (NA, NaN, Inf)
# (devido a V = -1 e ter x = 1, então V + x = 0 no denominador).
n0 <- nls(y ~ A * x/(V + x),
start = c(A = 7, V = -1),
trace = TRUE)
theta0 <- c(7, -1)
at_theta <- d3(x, A = theta0[1], V = theta0[2])
f_pred <- c(at_theta)
f_grad <- attr(at_theta, "gradient")
f_grad
# 3) Convergência para mínimo local (devido a valor inicial
# inapropriado ou fora do espaço paramétrico).
n0 <- nls(y ~ A * x/(V + x),
start = c(A = 7, V = -1.1),
trace = TRUE)
# 4) Gradiente singular por valores iniciais distantes.
n0 <- nls(y ~ A * x/(V + x),
start = c(A = -17, V = 100),
trace = TRUE)
# 5) Modelo completamente não identificável.
n0 <- nls(y ~ A * B * x/(V + x),
start = c(A = 5, B = 2, V = 1),
trace = TRUE)
n0 <- nls(y ~ A^B * x/(V + x),
start = c(A = 3, B = 2, V = 1),
trace = TRUE)
# Fator de passos reduzido: pouca curvatura ao redor do ponto
# estacionário, relacionado à baixa identificabilidade do modelo,
# correlações altas.
# 6) Modelo incompatível com os dados.
z <- x
plot(z ~ x)
n0 <- nls(z ~ A * x/(V + x),
start = c(A = 3, V = 1),
trace = TRUE)4 A superfície de mínimos quadrados
#-----------------------------------------------------------------------
# Valores iniciais e trajetória sobre a superfície da função objetivo.
# Função objetivo: RSS - residual sum of squares.
rss <- function(A, V, y, x) {
sum((y - (A * x)/(V + x))^2)
}
# Versão vetorizada.
RSS <- Vectorize(rss, c("A", "V"))
A_grid <- seq(0, 40, l = 100)
V_grid <- seq(0, 20, l = 100)
rss_surf <- outer(A_grid, V_grid, FUN = RSS, y = y, x = x)
contour(x = A_grid, y = V_grid, z = rss_surf,
levels = (1:35)^2,
xlab = "A", ylab = "V",
col = "gray70",
main = "Superfície da função RSS")
# lista de chutes iniciais
start_list <- list(s1 = c(A = 0.1, V = 0.1),
s2 = c(A = 40, V = 20),
s3 = c(A = 35, V = 2.5),
s4 = c(A = 18, V = 18))
# Gráficos que vão mostrar a trajetória.
oldpar <- par()
par(mfrow = c(2, 2), mar = c(4, 4, 1, 1))
for (lis in 1:4) {
contour(x = A_grid, y = V_grid, z = rss_surf,
levels = (seq(1, 35, 2))^2,
xlab = "A", ylab = "V", col = "gray70")
sink("trace.txt")
n0 <- nls(y ~ A * x/(V + x),
start = start_list[[lis]],
trace = TRUE)
sink()
trace <- read.table("trace.txt")
for (i in seq(nrow(trace) - 1)) {
arrows(trace[i, "V3"], trace[i, "V4"],
trace[i + 1, "V3"], trace[i + 1, "V4"],
col = 2, length = 0.1)
abline(v = trace[i + 1, "V3"],
h = trace[i + 1, "V4"],
col = "orange", lty = 3)
Sys.sleep(1)
print(c(i, trace[i + 1, "V3"], trace[i + 1, "V4"]))
}
}
sink()
par(oldpar)
# agora é conveniente interpretar a matriz de covariância das estimativas!
vcov(n0)
cov2cor(vcov(n0))
#-----------------------------------------------------------------------
# Valores iniciais inadequados podem levar à mínimos locais.
# Clique sobre a superfície de contornos para partir a estimação
# do ponto clicado.
A_grid <- seq(-5, 20, l = 100)
V_grid <- seq(-3, 10, l = 100)
rss_surf <- outer(A_grid, V_grid, RSS, y, x)
layout(1)
contour(x = A_grid, y = V_grid, z = rss_surf,
levels = (1:35)^2, xlab = "A", ylab = "V",
col = "gray70", main = "Superfície da função RSS")
start_click <- locator(n = 1)
names(start_click) <- c("A", "V")
sink("trace.txt")
n0 <- nls(y ~ A * x/(V + x), start = start_click, trace = TRUE)
sink()
trace <- read.table("trace.txt")
for (i in seq(nrow(trace) - 1)) {
arrows(trace[i, "V3"], trace[i, "V4"],
trace[i + 1, "V3"], trace[i + 1, "V4"],
col = 2, length = 0.1)
Sys.sleep(1)
}5 Estimação por máxima verossimilhança
#-----------------------------------------------------------------------
# Inferência baseada em verossimilhança.
set.seed(321)
x <- 1:10
y <- 1 - exp(-log(2) * x/2) + rnorm(x, 0, 0.05)
plot(y ~ x)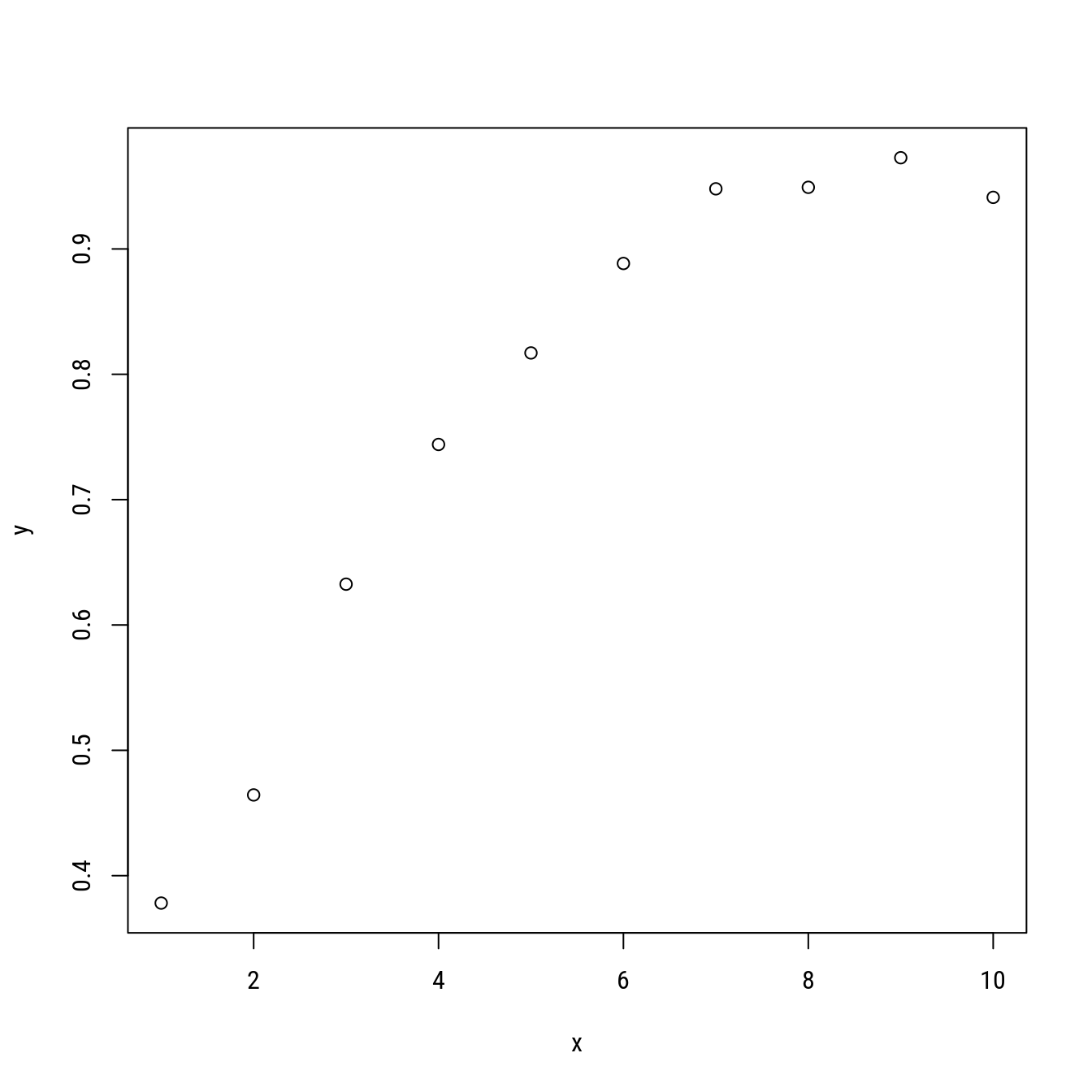
# Parametrizações do modelo monomolecular (assíntota fixada em 1):
# 1. Com parâmetro theta_c (taxa na origem):
# 1 - exp(-thc * x)
# 2. Com parâmetro theta_v (tempo de meia vida):
# 1 - exp(-log(2) * x/thv)
#-----------------------------------------------------------------------
# Funções de log-verossimilhança.
llc <- function(thc, x, y) {
m <- 1 - exp(-thc * x)
s <- sqrt(sum((y - m)^2)/length(y))
sum(dnorm(y, m, s, log = TRUE))
}
llv <- function(thv, x, y) {
m <- 1 - exp(-log(2) * x/thv)
s <- sqrt(sum((y - m)^2)/length(y))
sum(dnorm(y, m, s, log = TRUE))
}
#-----------------------------------------------------------------------
# Visualizando a função de ll.
len <- 100
thv_g <- seq(1.7, 2.3, l = 40)
llv_g <- sapply(thv_g, llv, x = x, y = y)
thc_g <- seq(log(2)/max(thv_g), log(2)/min(thv_g), l = 40)
llc_g <- sapply(thc_g, llc, x = x, y = y)
par(mfrow = c(1, 2))
plot(llc_g ~ thc_g, type = "l")
plot(llv_g ~ thv_g, type = "l")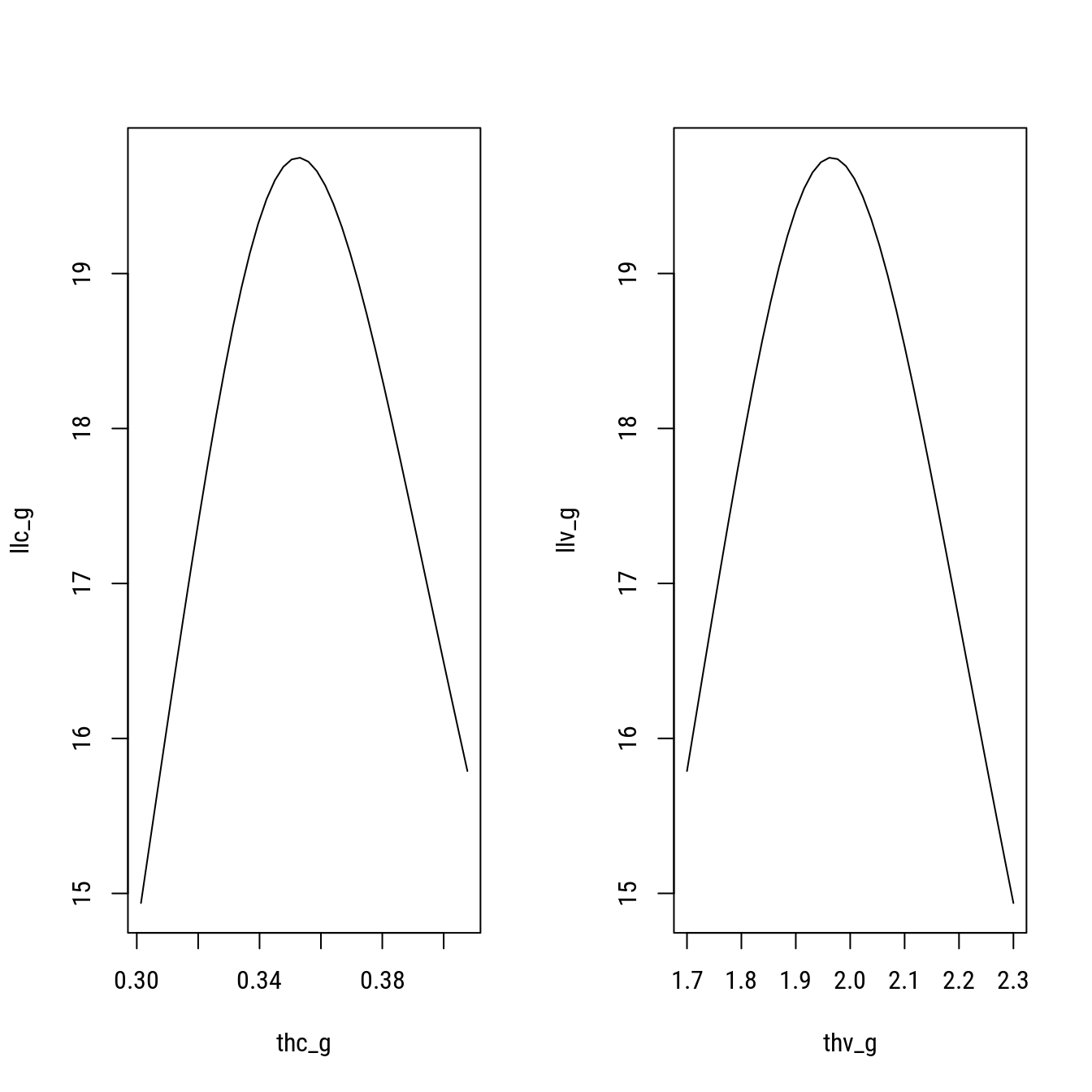
layout(1)
#-----------------------------------------------------------------------
# Estimando os parâmetros por máxima verossimilhança.
opc <- optim(c(log(2)/2),
fn = llc,
x = x,
y = y,
method = "BFGS",
control = list(fnscale = -1),
hessian = TRUE)
opv <- optim(c(2),
fn = llv,
x = x,
y = y,
method = "BFGS",
control = list(fnscale = -1),
hessian = TRUE)
(thc <- opc$par)## [1] 0.3526312(thv <- opv$par)## [1] 1.965643log(2)/thv## [1] 0.3526313(llthc <- opc$value)## [1] 19.74808(llthv <- opv$value)## [1] 19.74808(vthc <- -1/c(opc$hessian))## [1] 0.0002030686(vthv <- -1/c(opv$hessian))## [1] 0.006304035qchi <- qchisq(0.95, df = 1)
qnor <- qnorm(0.975)
#-----------------------------------------------------------------------
# Visualizando a log-verossimilhança e a deviance.
par(mfrow = c(2, 2))
# 1
plot(llc_g ~ thc_g,
type = "l", ylab = "log-verossimilhança",
xlab = expression(th[c]))
abline(v = thc, h = llthc - c(0, qchi), lty = 2)
# 2
devc <- -2 * (llc_g - llthc)
plot(devc ~ thc_g, type = "l",
ylab = "Deviance", xlab = expression(th[c]))
abline(v = thc, h = c(0, qchi), lty = 2)
curve(((x - thc)^2/vthc), add = TRUE, col = 2)
# 3
plot(llv_g ~ thv_g,
type = "l", ylab = "log-verossimilhança",
xlab = expression(th[v]))
abline(v = thv, h = llthv - c(0, qchi), lty = 2)
# 4
devv <- -2 * (llv_g - llthv)
plot(devv ~ thv_g, type = "l",
ylab = "Deviance", xlab = expression(th[v]))
abline(v = thv, h = c(0, qchi), lty = 2)
curve(((x - thv)^2/vthv), add = TRUE, col = 2)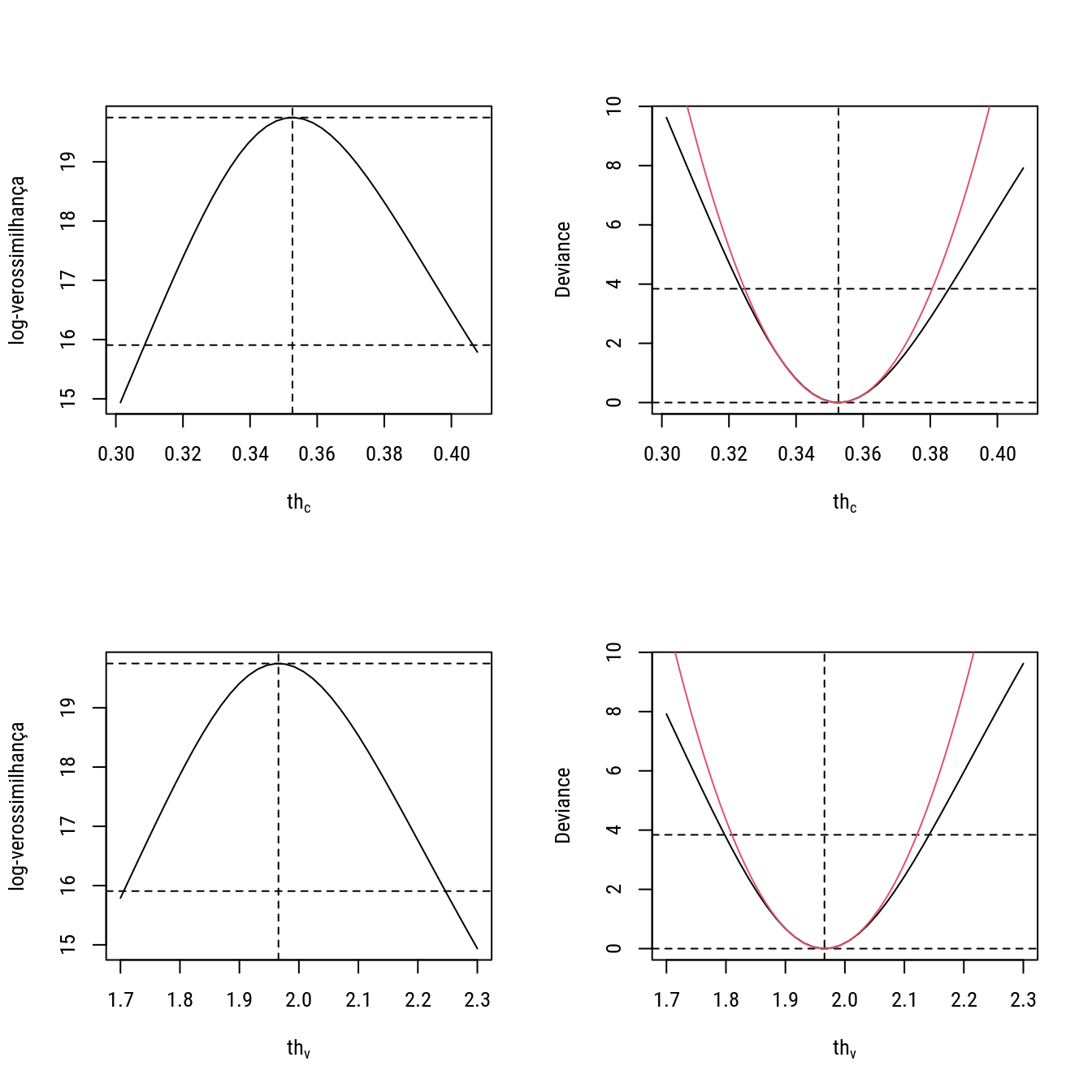
layout(1)
#-----------------------------------------------------------------------
# Funções de verossimilhança na escala da deviance para obter IC.
dev_c <- function(thc0, llthc, qchi, x, y) {
dev <- sapply(thc0, function(thc00) {
m0 <- 1 - exp(-thc00 * x)
s0 <- sqrt(sum((y - m0)^2)/length(y))
ll0 <- sum(dnorm(y, m0, s0, log = TRUE))
dev <- -2 * (ll0 - llthc)
})
return(dev - qchi)
}
dev_v <- function(thv0, llthv, qchi, x, y) {
dev <- sapply(thv0, function(thv00) {
m0 <- 1 - exp(-log(2) * x/thv00)
s0 <- sqrt(sum((y - m0)^2)/length(y))
ll0 <- sum(dnorm(y, m0, s0, log = TRUE))
dev <- -2 * (ll0 - llthv)
})
return(dev - qchi)
}
#-----------------------------------------------------------------------
# Obtendo os IC baseados na deviance e na aproximação quadrática.
thc_lim <- uniroot.all(dev_c, interval = c(0.3, 0.4), llthc = llthc,
qchi = qchi, x = x, y = y)
thc_lim## [1] 0.3236300 0.3855434thv_lim <- uniroot.all(dev_v, interval = c(1, 3), llthv = llthv,
qchi = qchi, x = x, y = y)
thv_lim## [1] 1.797884 2.141702thc_piv <- thc + c(-1, 1) * qnor * sqrt(vthc)
thv_piv <- thv + c(-1, 1) * qnor * sqrt(vthv)
#-----------------------------------------------------------------------
# Verificando as diferenças com relação aos extremos do IC.
par(mfrow = c(1, 2))
# 1
devv <- -2 * (llv_g - llthv)
plot(devv ~ thv_g, type = "l",
ylab = "Deviance", xlab = expression(th[v]))
abline(v = thv, h = c(0, qchi), lty = 2)
curve(((x - thv)^2/vthv), add = TRUE, col = 2)
abline(v = thv_lim, lty = 2)
abline(v = thv_piv, lty = 2, col = 2)
# 2
devc <- -2 * (llc_g - llthc)
plot(devc ~ thc_g, type = "l",
ylab = "Deviance", xlab = expression(th[c]))
abline(v = thc, h = c(0, qchi), lty = 2)
curve(((x - thc)^2/vthc), add = TRUE, col = 2)
abline(v = thc_lim, lty = 2)
abline(v = thc_piv, lty = 2, col = 2)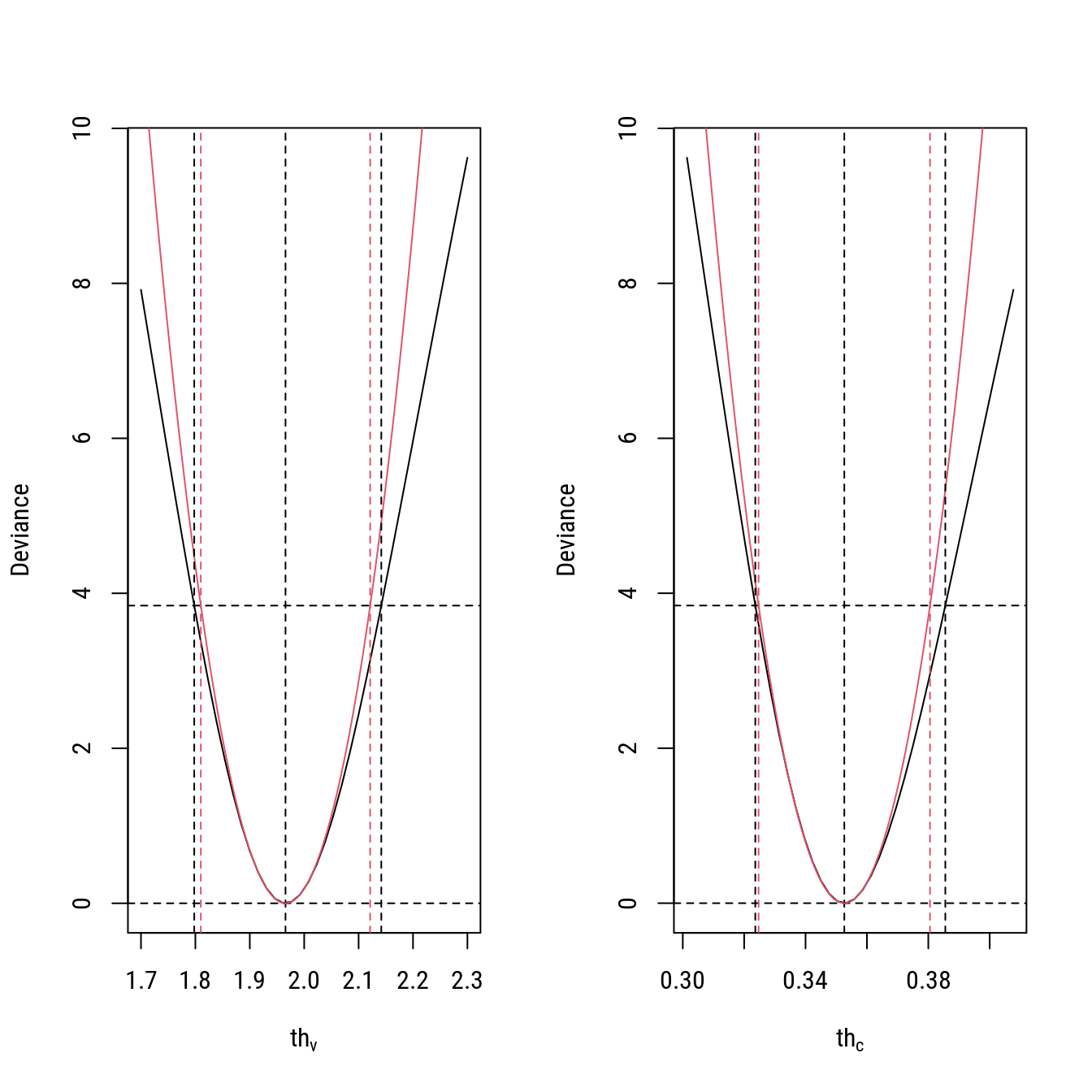
layout(1)
#-----------------------------------------------------------------------
# Intervalos de confiança baseados na deviance e na aproximação
# quadrática (Wald ou assintótico).
n0 <- nls(y ~ 1 - exp(-b * x/2),
start = list(b = 1))
confint(n0)## 2.5% 97.5%
## 0.6417618 0.7782989confint.default(n0)## 2.5 % 97.5 %
## b 0.6464826 0.7640425#-----------------------------------------------------------------------|
Modelos de Regressão Não Linear: Fundamentos e Aplicações em R leg.ufpr.br/~walmes/cursoR/mrnl |
Prof. Walmes M. Zeviani Departamento de Estatística · UFPR |