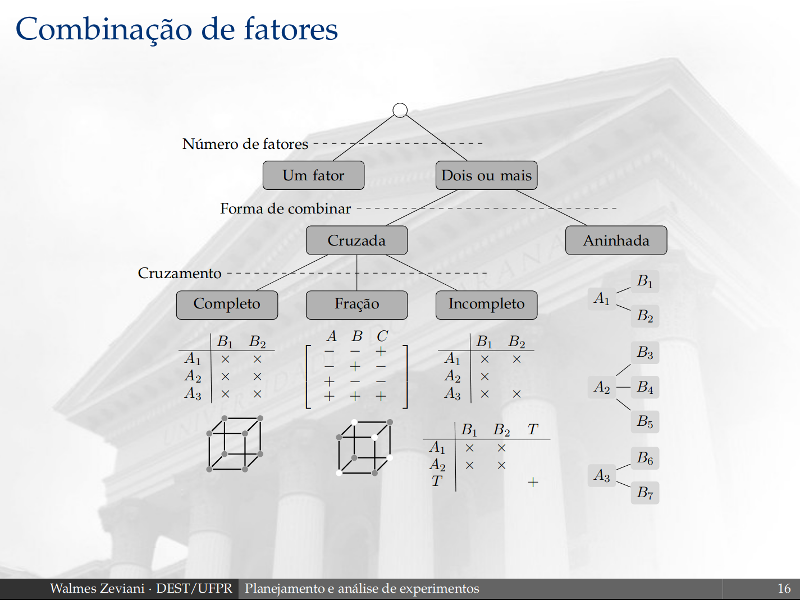
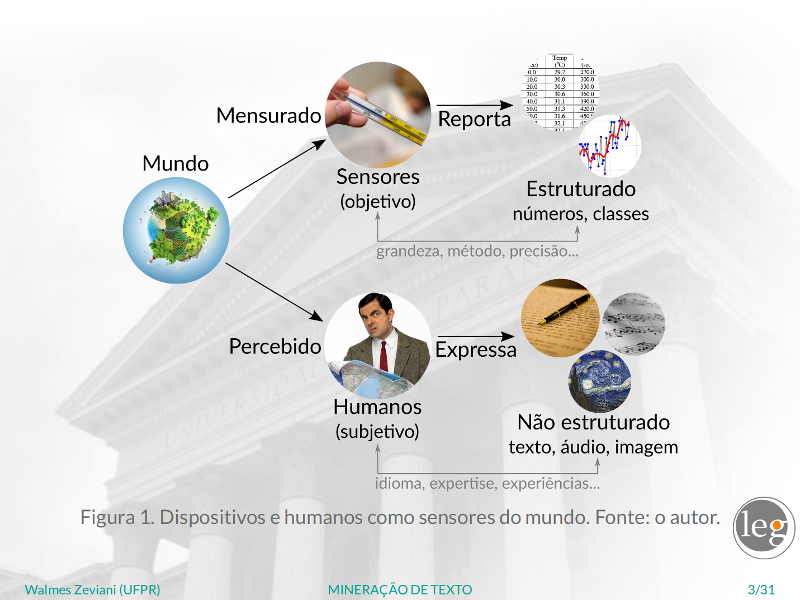
Visualização de dados
Fundamentos, precauções e tendências
- Alunos de Pós Graduação em Engenharia Florestal UFPR
- 24 de Agosto de 2018
- Biofix, Campus Jardim Botânico, UFPR · Curitiba/PR
Visualização de dados é um importante aspecto na análise de dados. Com a era do Big Data, a visualização de dados toma ainda maior relevância tornando-se uma linguagem para compreensão dos dados e comunicação dos resultados, usada para rapidamente reagir a informação exposta pelos dados. Nesse seminário é discutida a importância da visualização de dados, abordado aspectos da sua história e discutidas as principais tendências. Da metade em diante, aspectos fundamentos da visualização efetiva são comentados, bem como feitas recomendações e precauções sobre o uso correto de gráficos. O landscape de recursos gráficos do R é apresentado.