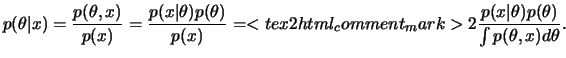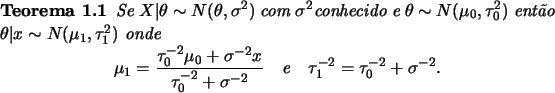A informação que se tem sobre uma quantidade de interesse
![]() é fundamental na Estatística. O verdadeiro valor de
é fundamental na Estatística. O verdadeiro valor de ![]() é desconhecido e a idéia é tentar reduzir este desconhecimento. Além
disso, a intensidade da incerteza a respeito de
é desconhecido e a idéia é tentar reduzir este desconhecimento. Além
disso, a intensidade da incerteza a respeito de ![]() pode assumir
diferentes graus. Do ponto de vista Bayesiano, estes diferentes graus de
incerteza são representados através de modelos probabilísticos para
pode assumir
diferentes graus. Do ponto de vista Bayesiano, estes diferentes graus de
incerteza são representados através de modelos probabilísticos para ![]() . Neste contexto, é natural que diferentes
pesquisadores possam ter diferentes graus de incerteza sobre
. Neste contexto, é natural que diferentes
pesquisadores possam ter diferentes graus de incerteza sobre ![]() (especificando modelos distintos). Sendo assim, não existe nenhuma
distinção entre quantidades observáveis e os parâmetros de um
modelo estatístico, todos são considerados quantidades aleatórias.
(especificando modelos distintos). Sendo assim, não existe nenhuma
distinção entre quantidades observáveis e os parâmetros de um
modelo estatístico, todos são considerados quantidades aleatórias.
Considere uma quantidade de interesse desconhecida ![]() (tipicamente
não observável). A informação de que dispomos sobre
(tipicamente
não observável). A informação de que dispomos sobre ![]() ,
resumida probabilisticamente através de
,
resumida probabilisticamente através de ![]() , pode ser aumentada
observando-se uma quantidade aleatória
, pode ser aumentada
observando-se uma quantidade aleatória ![]() relacionada com
relacionada com ![]() . A
distribuição amostral
. A
distribuição amostral
![]() define esta relação. A idéia
de que após observar
define esta relação. A idéia
de que após observar ![]() a quantidade de informação sobre
a quantidade de informação sobre ![]() aumenta é bastante intuitiva e o teorema de Bayes é a regra de
atualização utilizada para quantificar este aumento de informação,
aumenta é bastante intuitiva e o teorema de Bayes é a regra de
atualização utilizada para quantificar este aumento de informação,
Para um valor fixo de ![]() , a função
, a função
![]() fornece a
plausibilidade ou verossimilhança de cada um dos
possíveis valores de
fornece a
plausibilidade ou verossimilhança de cada um dos
possíveis valores de ![]() enquanto
enquanto ![]() é chamada
distribuição a priori de
é chamada
distribuição a priori de ![]() . Estas duas fontes de
informação, priori e verossimilhança, são combinadas levando à
distribuição a posteriori de
. Estas duas fontes de
informação, priori e verossimilhança, são combinadas levando à
distribuição a posteriori de ![]() ,
,
![]() . Assim, a
forma usual do teorema de Bayes é
. Assim, a
forma usual do teorema de Bayes é
| (1.2) |
Note que, ao omitir o termo ![]() , a igualdade em (1.1) foi
substituída por uma proporcionalidade. Esta forma simplificada do
teorema de Bayes será útil em problemas que envolvam estimação de
parâmetros já que o denominador é apenas uma constante
normalizadora. Em outras situações, como seleção de modelos, este
termo tem um papel crucial.
, a igualdade em (1.1) foi
substituída por uma proporcionalidade. Esta forma simplificada do
teorema de Bayes será útil em problemas que envolvam estimação de
parâmetros já que o denominador é apenas uma constante
normalizadora. Em outras situações, como seleção de modelos, este
termo tem um papel crucial.
É intuitivo também que a probabilidade a posteriori de um particular
conjunto de valores de ![]() será pequena se
será pequena se ![]() ou
ou
![]() for pequena para este conjunto. Em particular, se atribuirmos
probabilidade a priori igual a zero para um conjunto de valores de
for pequena para este conjunto. Em particular, se atribuirmos
probabilidade a priori igual a zero para um conjunto de valores de ![]() então a probabilidade a posteriori será zero qualquer que seja a amostra
observada.
então a probabilidade a posteriori será zero qualquer que seja a amostra
observada.
A constante normalizadora da posteriori pode ser facilmente recuperada pois
![]() onde
onde
![$\displaystyle k^{-1}= \int p(x\vert\theta)p(\theta)d\theta=E_\theta[p(X\vert\theta)]= p(x)
$](img20.png)
Se, após observar ![]() , estamos interessados na previsão de uma
quantidade
, estamos interessados na previsão de uma
quantidade ![]() , também relacionada com
, também relacionada com ![]() , e descrita
probabilisticamente por
, e descrita
probabilisticamente por
![]() então
então
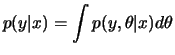 |
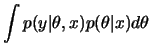 |
||
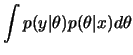 |
Fica claro também que os conceitos de priori e posteriori
são relativos àquela observação que está sendo considerada no
momento. Assim,
![]() é a posteriori de
é a posteriori de ![]() em relação a
em relação a
![]() (que já foi observado) mas é a priori de
(que já foi observado) mas é a priori de ![]() em relação a
em relação a ![]() (que não foi observado ainda). Após observar
(que não foi observado ainda). Após observar ![]() uma nova
posteriori (relativa a
uma nova
posteriori (relativa a ![]() e
e ![]() ) é obtida aplicando-se novamente o
teorema de Bayes. Mas será que esta posteriori final depende da ordem em
que as observações
) é obtida aplicando-se novamente o
teorema de Bayes. Mas será que esta posteriori final depende da ordem em
que as observações ![]() e
e ![]() foram processadas? Observando-se as
quantidades
foram processadas? Observando-se as
quantidades
![]() , independentes dado
, independentes dado ![]() e
relacionadas a
e
relacionadas a ![]() através de
através de
![]() segue que
segue que
![$\displaystyle \left[\,\prod_{i=1}^n
l_i(\theta;x_i)\right]p(\theta)$](img39.png) |
|||
(Gamerman e Migon, 1993) Um médico, ao examinar uma pessoa, `` desconfia'' que ela possa ter uma certa doença. Baseado na sua experiência, no seu conhecimento sobre esta doença e nas informações dadas pelo paciente ele assume que a probabilidade do paciente ter a doença é 0,7. Aqui a quantidade de interesse desconhecida é o indicador de doença

É bem intuitivo que a probabilidade de doença deve ter aumentado após este resultado e a questão aqui é quantificar este aumento. Usando o teorema de Bayes segue que
Agora o médico aplica outro teste ![]() cujo resultado está
relacionado a
cujo resultado está
relacionado a ![]() através da seguinte distribuição
através da seguinte distribuição
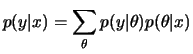
O resultado deste teste foi negativo (![]() ). Neste caso, é também
intuitivo que a probabilidade de doença deve ter diminuido e esta redução será quantificada por uma nova aplicação do teorema de Bayes,
). Neste caso, é também
intuitivo que a probabilidade de doença deve ter diminuido e esta redução será quantificada por uma nova aplicação do teorema de Bayes,
Verifique como a probabilidade de doença se alterou ao longo do experimento

Um outro resultado importante ocorre quando se tem uma única observação da distribuição normal com média desconhecida. Se a média tiver priori normal então os parâmetros da posteriori são obtidos de uma forma bastante intuitiva.
Note que, definindo precisão como o inverso da variância,
segue do teorema que a precisão a posteriori é a soma das precisões a
priori e da verossimilhança e não depende de ![]() . Interpretando
precisão como uma medida de informação e definindo
. Interpretando
precisão como uma medida de informação e definindo
![]() então
então ![]() mede a
informação relativa contida na priori com respeito à informação
total. Podemos escrever então que
mede a
informação relativa contida na priori com respeito à informação
total. Podemos escrever então que
(Box & Tiao, 1992) Os físicos ![]() e
e ![]() desejam
determinar uma constante física
desejam
determinar uma constante física ![]() . O físico
. O físico ![]() tem mais
experiência nesta área e especifica sua priori como
tem mais
experiência nesta área e especifica sua priori como
![]() . O físico
. O físico ![]() tem pouca experiência e especifica uma
priori muito mais incerta em relação à posição de
tem pouca experiência e especifica uma
priori muito mais incerta em relação à posição de ![]() ,
,
![]() . Assim, não é difícil verificar que
. Assim, não é difícil verificar que
Faz-se então uma medição ![]() de
de ![]() em laboratório com um
aparelho calibrado com distribuição amostral
em laboratório com um
aparelho calibrado com distribuição amostral
![]() e observou-se
e observou-se ![]() . Aplicando o teorema 1.1 segue que
. Aplicando o teorema 1.1 segue que
Note também que os aumentos nas precisões a posteriori em relação às precisões a priori foram,
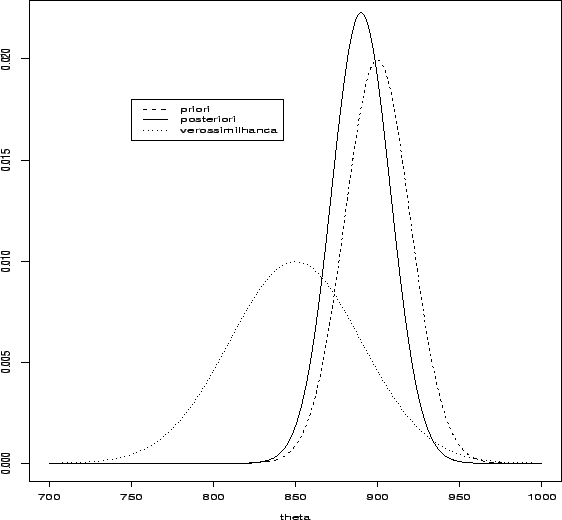
A situação está representada graficamente na Figura 1.1 a
seguir. Note como a distribuição a posteriori representa um
compromisso entre a distribuição a priori e a verossimilhança. Além
disso, como as incertezas iniciais são bem diferentes o mesmo
experimento fornece muito pouca informação adicional para o físico ![]() enquanto que a incerteza do físico
enquanto que a incerteza do físico ![]() foi bastante reduzida.
foi bastante reduzida.
O exemplo a seguir (DeGroot, 1970, páginas 165 e 166) ilustra esta
propriedade. Imagine que cada item de uma população de itens
manufaturados pode ser classificado como defeituoso ou não defeituoso. A
proporção ![]() de itens defeituosos na população é
desconhecida e uma amostra de itens será selecionada de acordo com um dos
seguintes métodos:
de itens defeituosos na população é
desconhecida e uma amostra de itens será selecionada de acordo com um dos
seguintes métodos:
Qualquer que tenha sido o esquema amostral, se foram inspecionados ![]() itens
itens
![]() dos quais
dos quais ![]() eram defeituosos então
eram defeituosos então
O Princípio da Verossimilhança postula que para fazer inferência
sobre uma quantidade de interesse ![]() só importa aquilo que foi
realmente observado e não aquilo que `` poderia'' ter ocorrido
mas efetivamente não ocorreu.
só importa aquilo que foi
realmente observado e não aquilo que `` poderia'' ter ocorrido
mas efetivamente não ocorreu.
(a) Que proporção dos itens serão classificados como suspeitos ?
(b) Qual a probabilidade de um item classificado como suspeito ser defeituoso ?
(c) Outro teste, que classifica ![]() dos itens defeituosos e
dos itens defeituosos e ![]() dos itens bons como defeituosos,
é aplicado somente aos itens suspeitos.
(d) Que proporção de itens terão a suspeita de defeito confirmada ?
(e) Qual a probabilidade de um item reprovado neste
dos itens bons como defeituosos,
é aplicado somente aos itens suspeitos.
(d) Que proporção de itens terão a suspeita de defeito confirmada ?
(e) Qual a probabilidade de um item reprovado neste
![]() teste ser defeituoso ?
teste ser defeituoso ?