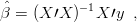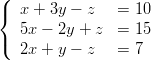
Os tipos básicos de objetos do Rsão:
Os quatro primeiros tipos são objetos que armazenam dados e que diferem entre si na forma da armazenar e operar com os dados. O último (função) é um tipo objeto especial que recebe algum "input"e produz um "output".
Experimente os comandos listados para se familiarizar com estas estruturas. Note que usamos as funções do tipo is.*() para testar se um objeto é de um determinado tipo. Estas funções são is.vector(), is.matrix(), is.array(), is.data.frame(), is.list(), is.function().
Vetores são o tipo básico e mais simples de objeto para armazenar dados no R. O R é uma linguagem vetorial, e portanto capaz de operar vetores e matrizes diretamente sem a necessidade de "loops", como por exemplo em códigos C e/ou Fortran.
Nos exemplo a seguir mostramos algumas operações com vetores. A função c() ("c" de concaternar) é usada para criar um vetor. Os colchetes [ ] são usados para indicar seleção de elementos. As funções rep(), seq() e o símbolo ":" são usadas para facilitar a criação de vetores que tenham alguma lei de formação.
Um escalar é um vetor de comprimento igual a 1. Os vetores podem ser compostos de números e caracteres ou apenas de um destes tipos. Portanto, adicionando um caracter a um vetor numérico este é transformado em um vetor alfanumérico.
Diversas operações numéricas podem ser feitas sobre vetores. Uma característica importante da linguagem é a "lei da reciclagem" que permite operações sobre vetores de tamanhos diferentes.
Vetores são uma estrutura de dados sobre a qual podemos aplicar funções como por exemplo as que fornecem medidas estatísticas.
Criando vetores com elementos repetidos
As funções rep() e seq() do R são úteis para criar vetores de dados que seguem um certo
padrão.
Clique aqui para ver um arquivo de dados.
vamos ver os comandos que podem ser usados para criar vetores para cada uma das três colunas iniciais
deste arquivo.
A primeira coluna pode ser obtida com um dos dois comandos mostrados inicialmente, a seguir. Os demais reproduzem a segunda e terceira coluna do arquivo de dados.
Vetores lógicos e seleção de elementos Como dito anteriormente os colchetes [] são usados para selecionar elementos de um vetor. No exemplo abaixo vemos como selecionar os 3 primeiros elementos do vetor x9 criado anteriormente e depois os elementos em posição par no vetor (segundo, quarto, sexto, oitavo e décimo)
Entretanto, a seleção de elementos é mais geral podendo atender a critérios definidos pelo usuário. A seguir mostramos que podemos criar um vetor lógico ind.72 que indica se cada valor de x9 é ou não maior que 72. O vetor pode ser ainda convertido para o formato de uma variável indicadora ("dummy").
Vetores de caracteres Vetores de caracteres também são criados por c() com elementos entre aspas. Há também algumas funções para criação automática.
Uma função particularmente útil para criar vetores de caracteres é paste(). Examine os seguintes comandos.
Vejamos ainda mais um exemplo. Considere criar um vetor com elementos:
T1 T1 T1 T1 T2 T2 T2 T2 T3 T3 T3
|
Fatores Comentamos anteriormente que os vetores podem ser numéricos ou de caracteres. Entretanto há mais um tipo importante de objeto: os fatores. Por exemplo, ao criar um vetor de indicadores de “tratamentos” em uma análise de experimentos devemos declarar este vetor como um “fator”. Portanto revisitando o exemplo visto anteriormente temos que uma forma mais adequada de usar o vetor como variável indicadora de tratamentos é defini-lo como um fator. Note que neste caso, diferentemente do anterior, são registrados os “níveis” (levels) do fator.
É importante notar a diferença entre um vetor de caracteres e um vetor que seja um fator que são objetos de classes diferentes. O primeiro simplesmente guarda os seus elementos enquanto o segundo possui atributos que nesta caso incluem os níveis do fator. Nos comandos abaixo esta distinção fica mais clara onde um vetor é criado inicialmente como numérico e depois convertido para fator.
Um fato relevante a respeito da manipulação de fator é que uma seleção de parte dele que exclua um certo valor não exclui este valor dos atributos do vetor como no caso abaixo.
Da mesma forma pode-se criar um vetor e definir para eles níveis, mesmos que estes níveis não estejam entre os elementos atualmente existentes no vetor. Note no exemplo abixo o que acontece com o valor "MG" em cada caso.
Fatores Ordenados Um tipo especial de fator é dado pelos fatores ordenados que são fatores para os quais preserva-se a ordenação natural dos níveis. No próximo exemplo vemos um vetor inicialmente definido como de caracteres e a diferença entre defini-lo como não-ordenado ou ordenado. A ordenação segue a ordem alfabética a menos que uma ordenação diferente seja definida pelo usuário no argumento levels. Note ainda é pode-se usar duas funções diferentes para definir fatores ordenados: factor(..., ord=T) ou ordered().
Mais algumas operações com vetores Considere o vetor vec obtido como se segue. As funções abaixo mostram como inverter a ordem dos elementos do vetor (rev()), ordenar os elementos ((sort()) e a posição de cada elemento no vetor ordenado e encontrar o "rank"dos elementos (rank()). As operações %% e %% fornecem, respectivamente, o resto e a parte inteira de uma divisão.
A função which retorna a posição do(s) elemento(s) que obedece a certo critério.
Outra operação é a remoção de elementos de vetores através de índices negativos.
Para mais detalhes sobre vetores você pode consultar ainda as seguinte páginas:
Matrizes são montadas a partir da reorganização de elementos de um vetor em linhas e colunas. Por “default” a matrix é preenchida por colunas e o argumento opcional byrow=T inverte este padrão. A seleção de elementos ou submatrizes é feita usando [,] sendo que antes da vírgula indica-se a(s) linha(s) e depois a(s) coluna(s) a serem selecionadas. Opcionalmente matrizes podem ter nomes associados às linhas e colunas ("rownames"e "colnames"). Cada um destes componentes da matrix é um vetor de nomes. Os comandos a seguir ilustram todas estas funcionalidades.
Matrizes são muitas vezes utilizadas para armazenar frequências de cruzamentos entre variáveis. Desta forma é comum surgir a necessidade de obter os totais marginais, isto é a soma dos elementos das linhas e/ou colunas das matrizes, o que pode ser diretamente obtido com margin.table(). No caso de matrizes estas operação produz o mesmo resultado que outras funções conforme mostramos a seguir.
Operações com matrizes Operações com matrizes são feitas diretamente assim como no caso de vetores. A "lei da reciclagem"permanece válida. Existem diversas operações sobre matrizes e vamos apresentar apenas algumas aqui. Note que as operações abaixo são todas realizadas elemento a elemento.
A multiplicação de matrizes é feita usando o operador %*%. A função t() faz transposição e a inversão é obtida com solve(). O pacote MASS fornece ginv() para obtenção de inversa generalizada (inversa de Moore-Penrose)
A função solve() na verdade é mais geral e fornece a solução de um sistema de equações lineares. Por exemplo, a solução do sistema:
pode ser obtida com:
Uma outra função muito útil para cálculos matriciais é crossprod() para produtos cruzados: crossprod(X) retorna X′X crossprod(X,Y) retorna X′Y . Deve ser dada preferência a esta função sempre que possível pois é mais precisa e rápida do que o correspondente produto matricial com transposição do objeto do primeiro argumento.
Como exemplo vamos considerar as variáveis preditora e resposta com valores fornecidos na Tabela 6.2 e considere obter os coeficientes da regressão linear dados por:
onde X é a matrix com os valores da variável X acrescida de uma coluna de 1’s e y são os valores da variável resposta.
|
Nos comandos abaixo mostramos como entrar com os dados e como obter os resultados de duas formas: (i) usando operações de matrizes de forma "ineficiente"e usando uma forma computacionalmente mais adequada de obter o mesmo resultado.
Notas:
Para mais detalhes sobre matrizes consulte a página:
O conceito de array generaliza a idéia de matrix. Enquanto em uma matrix os elementos são organizados em duas dimensões (linhas e colunas), em um array os elementos podem ser organizados em um número arbitrário de dimensões.
No R um array é definido utilizando a função array(). Defina um array com o comando a seguir e inspecione o objeto certificando-se que você entendeu como arrays são criados.
Examine agora os resultados dos seguintes comandos para selecionar e operar elementos do "array".
Podemos atribuir nomes às dimensões de um array.
Inspecione o “help” da função array (digite help(array)), rode e inspecione os exemplos contidos na documentação.
Veja agora um exemplo de dados já incluído no R no formato de array. Para “carregar” e visualizar os dados digite:
Para obter maiores informações sobre estes dados digite:
Agora vamos responder às seguintes perguntas, mostrando os comandos do R utilizados sobre o array de dados.
Note-se ainda que assim como em matrizes, margin.table() poderia ser utilizada para obter os totais marginais para cada dimensão do array de dados, fornecendo uma maneira alternativa à alguns dos comandos mostrados acima.
Esta função admite ainda índices múltiplos que permitem outros resumos da tabela de dados. Por exemplo mostramos a seguir como obter o total de sobreviventes e não sobreviventes, separados por sexo e depois as porcentagens de sobreviventes para cada sexo.
Vetores, matrizes e arrays forçam todos os elementos a serem do mesmo "tipo"i.e., ou numérico ou caracter. O "data-frame"é uma estrutura semelhante à uma matriz porém com cada coluna sendo tratada separadamente. Desta forma podemos ter colunas de valores numéricos e colunas de caracteres no mesmo objeto. Note entretanto que dentro de uma mesma coluna todos elementos ainda serão forçados a serem do mesmo tipo.
Na criação de data-frame expand.grid() pode ser muito útil gerando autimaticamente combinações de valores.
Para mais detalhes sobre data-frame consulte a página:
Listas são estruturas genéricas e flexíveis que permitem armazenar diversos formatos em um único objeto.
Uma lista é portanto uma coleção de objetos. Para listas há duas opções para se selecionar elementos: colchetes [ ] ou colchetes duplos [[ ]]. Entretanto os resultados retornados por cada um destes é diferente. Ou seja, o colchete simples ([ ]) retorna uma parte da lista, ou seja, retorna um objeto que ainda é uma lista. Já o colchete duplo ([[ ]]) retorna o objeto que está na posição indicada da lista. Examine o exemplo a seguir.
O conteúdo das funções podem ser vistos digitando o nome da função (sem os parênteses).
Entretanto isto não é disponível desta forma para todas as funções como por exemplo em min, max, rnorm e lines Nestes casos as funções não são escritas em linguagem R (em geral estão escritas em C) e para visualizar o conteúdo das funções você tem que examinar os arquivos do código fonte do R.
As funções do tipo is.*() mencionadas no início dasta sessão podem ser usadas para obter informações sobre a natureza de um objeto, o que pode sem muito útil quando se escreve funções em R. Entretanto são pouco práticas para determinar qual o tipo de um objeto e retornam apenas um valor lógico TRUE ou FALSE.
Uma função mais rica em detalhes é str() retorna informações sobre a estrutura do objeto. Nos exemplos a seguir vemos que a função informa sobre objecots que criamos anteriormente: x1 é um vetor numérico, estado é um fator om três níveis, ar1 é um array, d1 é um data.frame com duas variáveis sendo uma delas de valores inteiros e a outra de valores numéricos e lis1 é uma lista de dois elementos sendo o primeiro um vetor de caracteres e o segundo uma matrix de seis elementos e de dimensão 3 × 2.
e responda as seguintes perguntas fornecendo também o comando do R para obter a resposta:
| Fumante | Não Fumante
| ||||
| Idade | Masculino | Feminino | Masculino | Feminino | |
| Menor que 20 | 50 | 30 | 55 | 41 | |
| 20 a 40 | 39 | 28 | 31 | 30 | |
| Maior que 40 | 37 | 36 | 25 | 15 | |