Evolução da Severidade de Mancha Foliar de Glomerela em Macieira
Walmes Zeviani, Rafaele Regina Moreira & Louise Larissa May De Mio
2019-07-11
leaf_spot.RmdDefinições da Sessão
# https://github.com/walmes/wzRfun
# devtools::install_github("walmes/wzRfun")
# .libPaths("/usr/lib/R/site-library")
library(lattice)
library(latticeExtra)
library(plyr)
library(rootSolve) # gradient().
library(wzRfun) # panel.cbH().library(RDASC)Análise Exploratória
O experimento consistiu da observação da severidade da mancha foliar de Glomrella em ramos marcados de macieiras em dois pomares por 11 semanas. Em cada pomar, 30 plantas ao acaso tiveram um ramo marcado com 10 folhas. Aproximadamente a cada 7 dias, os ramos eram observados para a determinação da severidade de Glomerella em cada uma das folhas. Um total de 11 avaliações dos ramos foi feito produzindo 2 pomares \(\times\) 30 ramos \(\times\) 10 folhas \(\times\) 11 avaliações \(=\) 6600 observações de severidade.
As avaliações foram feitas nas mesmas datas em dois pomares indepedentes. Cada folha foi observada repetidamente nas 11 avaliações, exceto quando a folha caia do ramo. Sendo assim, um número de menor de folhas por ramo permanecia com o passar do tempo. Essas observações perdidas (missings) dificilmente foram perdidas ao acaso (missing at random), haja visto que o progresso da doença sobre as folhas é um fator que provoca a queda.
# Estrutura dos dados.
str(leaf_spot)## 'data.frame': 6600 obs. of 5 variables:
## $ pomar: num 1 1 1 1 1 1 1 1 1 1 ...
## $ dia : int 0 7 13 21 34 43 52 56 64 73 ...
## $ ramo : int 1 1 1 1 1 1 1 1 1 1 ...
## $ folha: int 1 1 1 1 1 1 1 1 1 1 ...
## $ sever: num 0 0.8 1.5 2 3.5 10.5 15.5 NA NA NA ...## dia 0 7 13 21 34 43 52 56 64 73 82
## pomar
## 1 300 300 300 300 300 300 300 300 300 300 300
## 2 300 300 300 300 300 300 300 300 300 300 300# Tabela de frequência de folhas presas ao ramo (sem folhas perdidas).
ftable(xtabs(~pomar + dia, data = na.omit(leaf_spot)))## dia 0 7 13 21 34 43 52 56 64 73 82
## pomar
## 1 300 299 292 286 237 237 237 100 44 21 12
## 2 300 297 297 295 293 293 293 203 80 27 23# Acesse a documentação para mais detalhes.
# help(leaf_spot, help_type = "html")
# Convertendo variáveis para fator.
leaf_spot <- within(leaf_spot, {
pomar <- factor(pomar, labels = c("I", "II"))
ramo <- factor(ramo)
folha <- interaction(ramo, folha, drop = TRUE)
})
xyplot(sever ~ dia | ramo,
groups = folha,
data = subset(leaf_spot, pomar == "I"),
type = "o",
xlab = "Dia de avaliação",
ylab = "Severidade da mancha foliar (%)",
main = "Pomar I",
as.table = TRUE)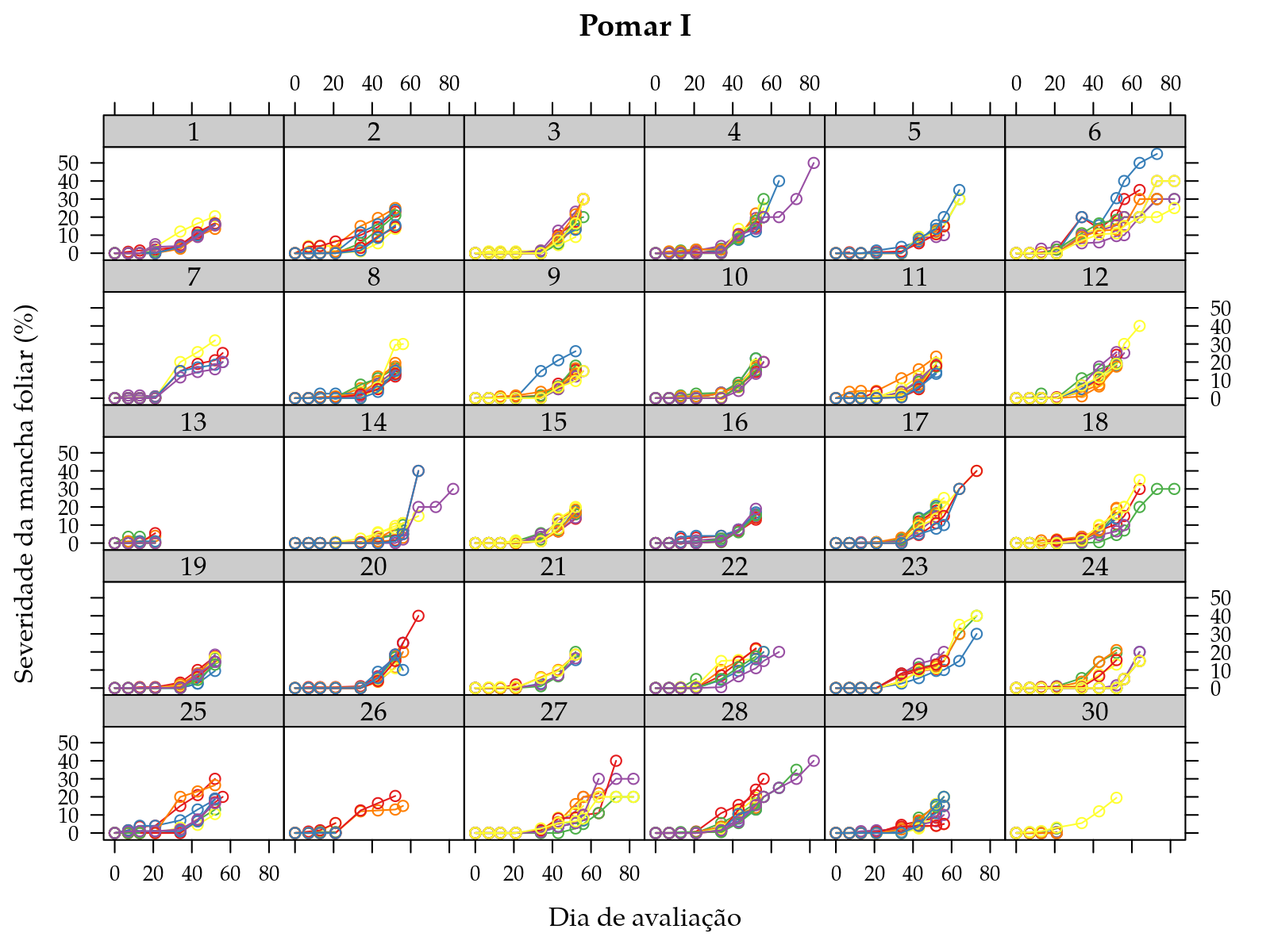
xyplot(sever ~ dia | ramo,
groups = folha,
data = subset(leaf_spot, pomar == "II"),
type = "o",
xlab = "Dia de avaliação",
ylab = "Severidade da mancha foliar (%)",
main = "Pomar II",
as.table = TRUE)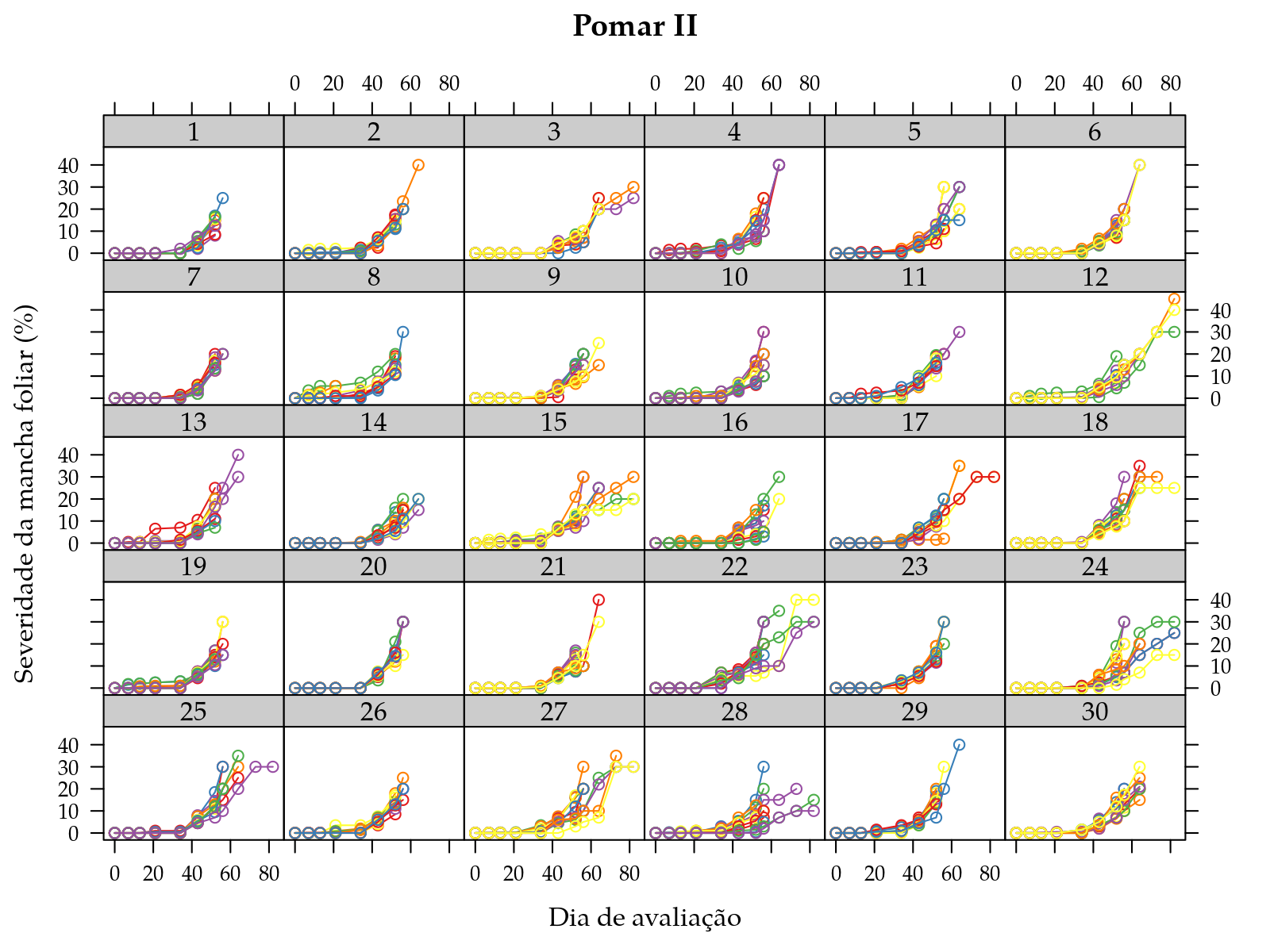
Pelos diagramas de dipersão, verifica-se que existe tanto variabilidade entre folhas de um mesmo ramo quanto entre ramos. O número de observações de cada folha também varia com o ramos. No pomar I, o ramo 13 teve poucas observações ao passo que o ramo 6 teve praticamente todas. Isso sugere que a forma como a doença se manifesta nos ramos depende de características locais não registradas, como a nutrição da planta, as condições de solo, a exposição do ramo ao sol, etc.
Ajuste de Modelo de Regressão Não Linear
da <- subset(leaf_spot, pomar == "I")
# Calibrando o chute inicial.
start <- list(A = 80, I = 80, S = 20)
xyplot(sever ~ dia, data = da) +
layer(panel.curve(A/(1 + exp(-(x - I)/S)), col = 2),
data = start)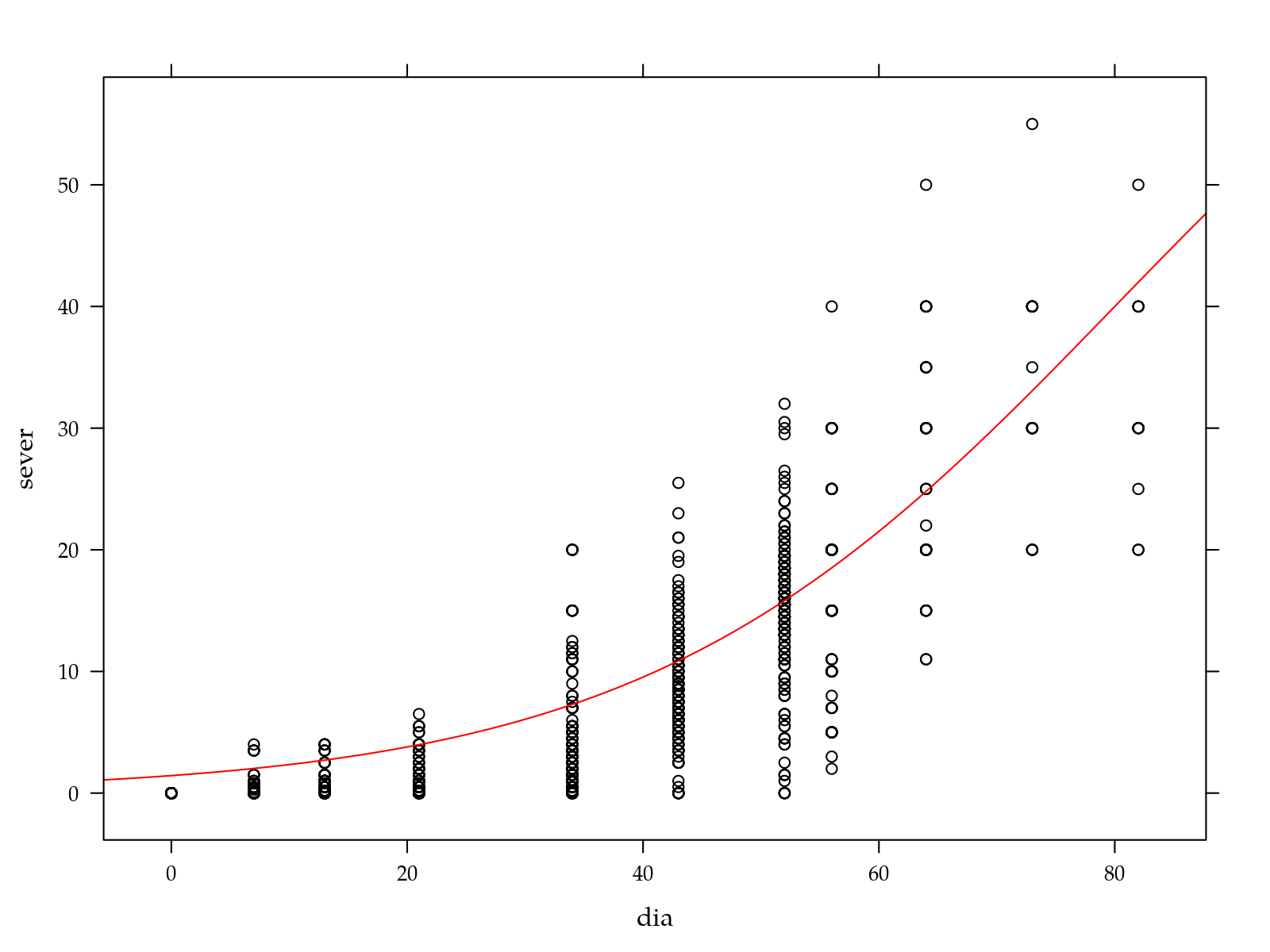
n0 <- nls(sever ~ A/(1 + exp(-(dia - I)/S)),
data = da,
start = start)
# Diagnóstico
m0 <- as.lm(n0)
par(mfrow = c(2, 2))
plot(m0)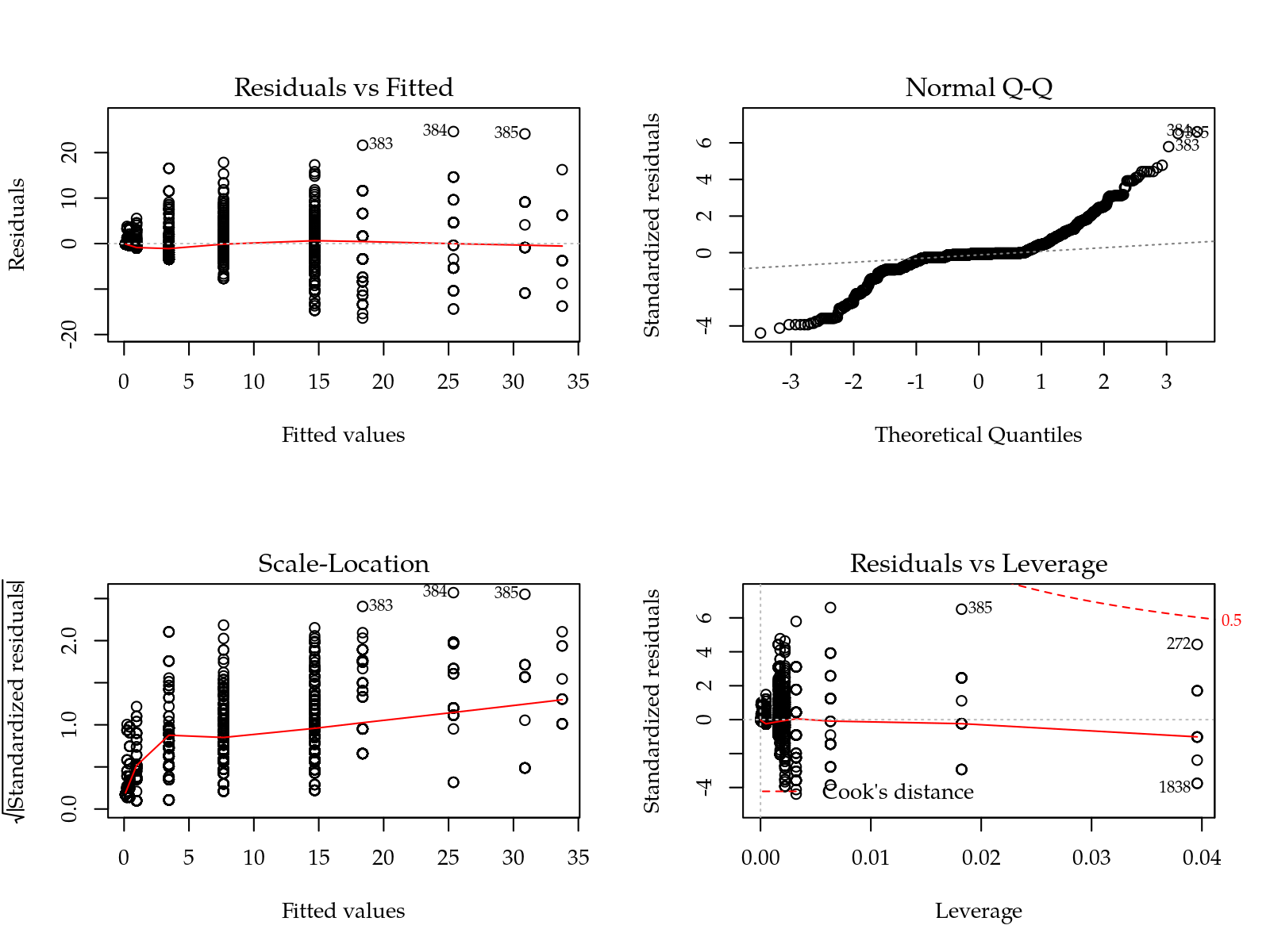
##
## Formula: sever ~ A/(1 + exp(-(dia - I)/S))
##
## Parameters:
## Estimate Std. Error t value Pr(>|t|)
## A 35.9119 1.0521 34.13 <2e-16 ***
## I 55.5444 0.6623 83.87 <2e-16 ***
## S 9.6198 0.3156 30.48 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 3.74 on 2062 degrees of freedom
##
## Number of iterations to convergence: 8
## Achieved convergence tolerance: 1.855e-06
## (1235 observations deleted due to missingness)## A
## 0.9332814# Resultado do ajuste.
xyplot(sever ~ dia, data = da) +
layer(panel.curve(A/(1 + exp(-(x - I)/S)), col = 2),
data = as.list(coef(n0)))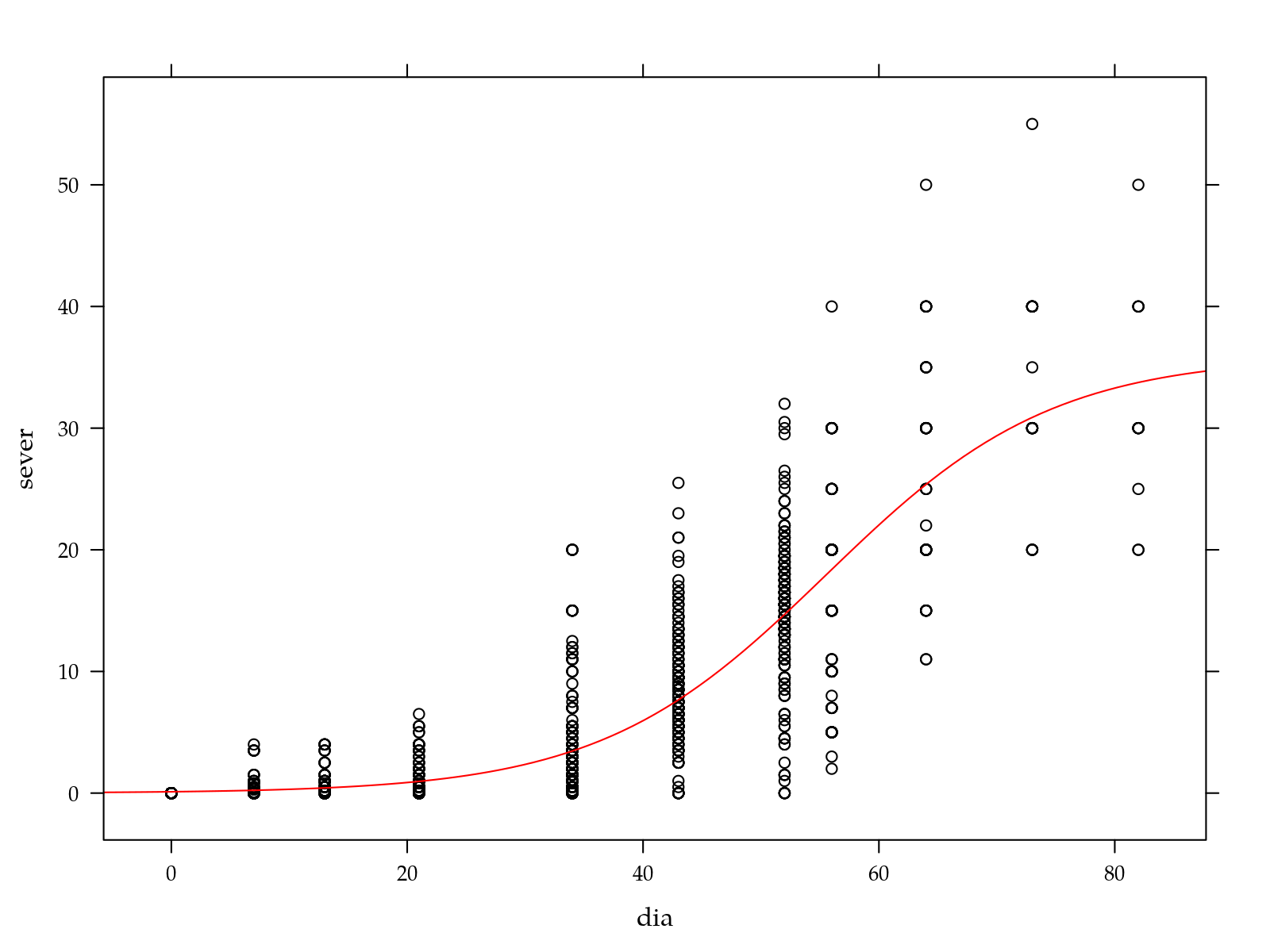
Ajuste de Modelo de Regressão Não Linear com Efeitos Aleatórios
library(nlme)
da <- da[complete.cases(da), ]
da <- groupedData(sever ~ dia | ramo/folha,
data = da,
order.groups = FALSE)
n1 <- nlme(sever ~ A/(1 + exp(-(dia - I)/S)),
fixed = A + I + S ~ 1,
random = I + S ~ 1 | ramo/folha,
data = da,
start = coef(n0))
logLik(n1)## 'log Lik.' -4465.499 (df=10)# n2 <- nlme(sever ~ A/(1 + exp(-(dia - I)/S)),
# fixed = A + I + S ~ 1,
# random = A + S ~ 1 | folha,
# data = da,
# start = coef(n0),
# control = list(maxIter = 100))
# logLik(n2)
# I + S ~ 1 | ramo/folha 'log Lik.' -4465.499 (df=10)
# I + S ~ 1 | folha 'log Lik.' -4516.702 (df=7)
# I ~ 1 | folha 'log Lik.' -4909.711 (df=5)
# A ~ 1 | folha 'log Lik.' -4968.641 (df=5)
# S ~ 1 | folha NA
# A + I ~ 1 | folha NA
# A + S ~ 1 | folha NA
# Estimativas.
summary(n1)## Nonlinear mixed-effects model fit by maximum likelihood
## Model: sever ~ A/(1 + exp(-(dia - I)/S))
## Data: da
## AIC BIC logLik
## 8950.998 9007.327 -4465.499
##
## Random effects:
## Formula: list(I ~ 1, S ~ 1)
## Level: ramo
## Structure: General positive-definite, Log-Cholesky parametrization
## StdDev Corr
## I 3.377137 I
## S 1.741725 0.065
##
## Formula: list(I ~ 1, S ~ 1)
## Level: folha %in% ramo
## Structure: General positive-definite, Log-Cholesky parametrization
## StdDev Corr
## I 4.489393 I
## S 2.355111 0.403
## Residual 1.591955
##
## Fixed effects: A + I + S ~ 1
## Value Std.Error DF t-value p-value
## A 49.46659 1.0744155 1763 46.04046 0
## I 59.08265 0.8039119 1763 73.49394 0
## S 9.22403 0.3753380 1763 24.57527 0
## Correlation:
## A I
## I 0.463
## S 0.203 0.249
##
## Standardized Within-Group Residuals:
## Min Q1 Med Q3 Max
## -5.256786817 -0.364848928 -0.089758791 0.002757017 6.326526014
##
## Number of Observations: 2065
## Number of Groups:
## ramo folha %in% ramo
## 30 300## A
## 1.340698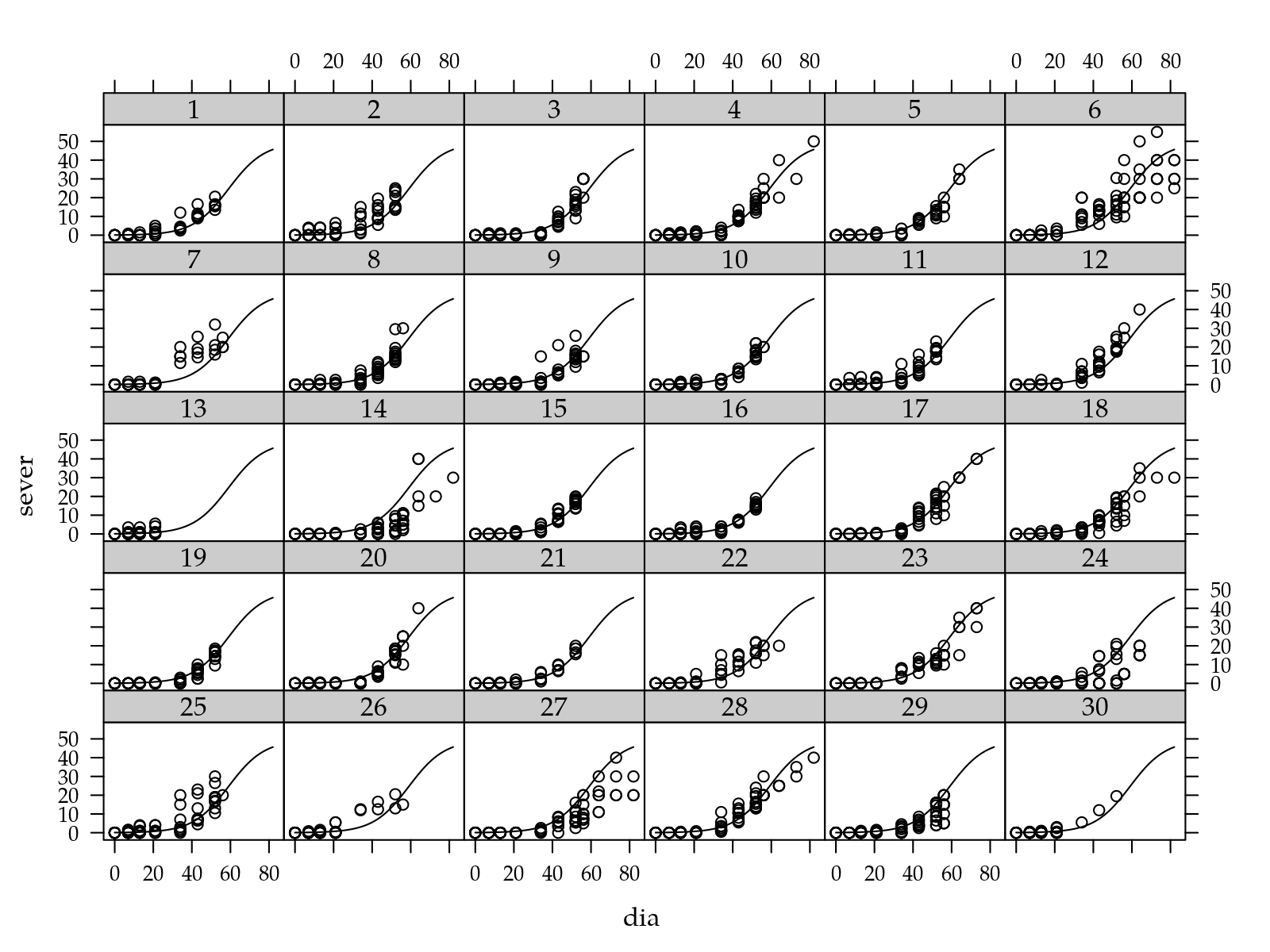
# Diagnóstico.
# r <- residuals(n1)
# f <- fitted(n1)
# xyplot(r ~ f)
# qqmath(r)Combinando os Resultados
# Estimates and standard error.
summary(n0)$coeff## Estimate Std. Error t value Pr(>|t|)
## A 35.911933 1.0520878 34.13397 8.085904e-203
## I 55.544355 0.6622642 83.87038 0.000000e+00
## S 9.619803 0.3155698 30.48392 8.369976e-169summary(n1)$tTable## Value Std.Error DF t-value p-value
## A 49.466588 1.0744155 1763 46.04046 1.437249e-304
## I 59.082649 0.8039119 1763 73.49394 0.000000e+00
## S 9.224033 0.3753380 1763 24.57527 6.299699e-115# Confidence intervals.
ci0 <- cbind(confint.default(n0), coef(n0))
ci1 <- intervals(n1)$fixed
ci1 <- ci1[, c(2, 1, 3)]
ci0 <- ci0[, c(3, 1, 2)]
colnames(ci0) <- colnames(ci1) <- c("est", "lwr", "upr")
ci <- as.data.frame(rbind(ci0, ci1))
ci$par <- factor(rownames(ci), levels = c("A", "I", "S"))
rownames(ci) <- NULL
ci$model <- gl(2, 3, labels = c("nls", "nlme"))
ci## est lwr upr par model
## 1 35.911933 33.849879 37.973987 A nls
## 2 55.544355 54.246341 56.842369 I nls
## 3 9.619803 9.001297 10.238308 S nls
## 4 49.466588 47.360857 51.572319 <NA> nlme
## 5 59.082649 57.507074 60.658224 <NA> nlme
## 6 9.224033 8.488414 9.959653 <NA> nlmesegplot(model ~ lwr + upr | par,
data = ci,
centers = est,
draw = FALSE,
scales = list(x = "free"),
layout = c(NA, 1),
ylab = "Modelo",
xlab = "Estimativa com IC de 95%")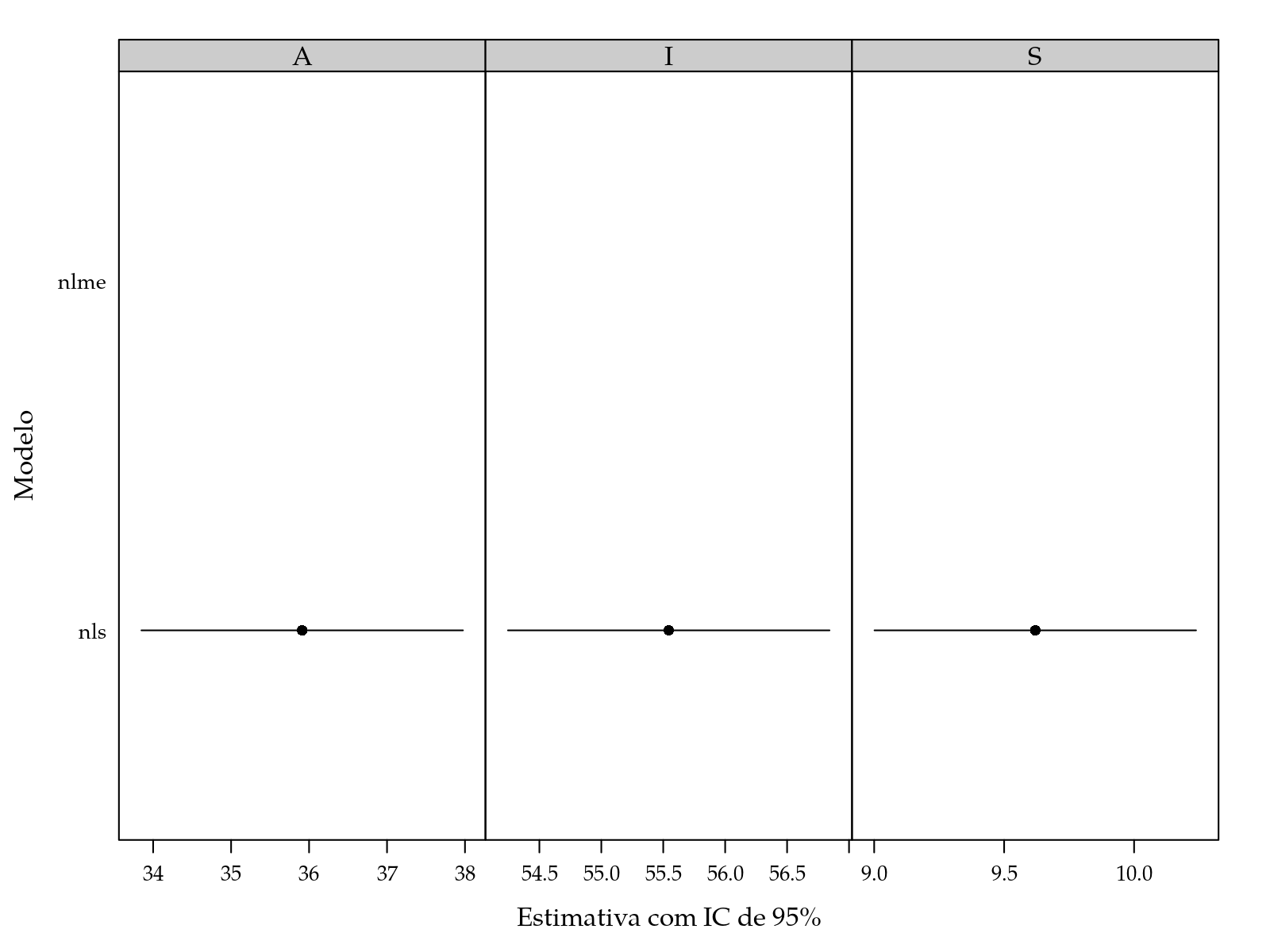
#-----------------------------------------------------------------------
# Random effects.
# a <- ranef(n1)
# str(a)
#
# qqmath(a$ramo$I)
# qqmath(a$ramo$S)
# splom(a$ramo)
#
# qqmath(a$folha$I)
# qqmath(a$folha$S)
# splom(a$folha)
#-----------------------------------------------------------------------
# Predição.
# Domínio para a predição.
pred <- expand.grid(dia = 0:85)
# Valores preditos.
pred$y0 <- predict(n0, newdata = pred)
pred$y1 <- predict(n1, newdata = pred, level = 0)
# Modelo escrito como função dos parâmetros (theta).
f <- function(theta, xx) {
with(as.list(theta),
A/(1 + exp(-(xx - I)/S)))
}
# Matriz com as derivadas parciais de theta no mle de theta.
F0 <- gradient(f, x = coef(n0), xx = pred$dia)
F1 <- gradient(f, x = fixef(n1), xx = pred$dia)
# Fatoração da matriz de covariância de theta.
U0 <- chol(vcov(n0))
U1 <- chol(vcov(n1))
pred$se0 <- sqrt(apply(F0 %*% t(U0), 1, function(x) sum(x^2)))
pred$se1 <- sqrt(apply(F1 %*% t(U1), 1, function(x) sum(x^2)))
zval <- qnorm(p = c(lwr = 0.025, fit = 0.5, upr = 0.975))
me <- outer(pred$se0, zval, "*")
b <- sweep(me, 1, pred$y0, "+")
colnames(b) <- paste(colnames(b), "0", sep = "")
pred <- cbind(pred, b)
me <- outer(pred$se1, zval, "*")
b <- sweep(me, 1, pred$y1, "+")
colnames(b) <- paste(colnames(b), "1", sep = "")
pred <- cbind(pred, b)
#-----------------------------------------------------------------------
# Predição para o nível de folha.
predue <- unique(subset(da, select = c(ramo, folha)))
dia <- seq(0, 85, by = 2)
predue <- predue[rep(1:nrow(predue), each = length(dia)), ]
predue$dia <- dia
str(predue)## 'data.frame': 12900 obs. of 3 variables:
## $ ramo : Factor w/ 30 levels "1","2","3","4",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ folha: Factor w/ 300 levels "1.1","1.2","1.3",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ dia : num 0 2 4 6 8 10 12 14 16 18 ...a <- predict(n1, newdata = predue, level = 2)
predue$y <- unlist(a)
#-----------------------------------------------------------------------
xyplot(sever ~ dia,
data = da,
jitter.x = TRUE,
pch = 19,
ylab = "Severidade da mancha foliar (%)",
xlab = "Dia da avaliação") +
as.layer(xyplot(y ~ dia,
data = predue,
col = "gray50",
type = "l",
groups = folha), under = TRUE) +
as.layer(xyplot(y0 ~ dia,
data = pred,
type = "l",
lty = 2,
lwd = 2,
prepanel = prepanel.cbH,
cty = "bands",
ly = pred$lwr0,
uy = pred$upr0,
fill = "red",
alpha = 0.6,
panel = panel.cbH)) +
as.layer(xyplot(y1 ~ dia,
data = pred,
type = "l",
lty = 1,
lwd = 2,
prepanel = prepanel.cbH,
cty = "bands",
ly = pred$lwr1,
uy = pred$upr1,
fill = "blue",
alpha = 0.6,
panel = panel.cbH))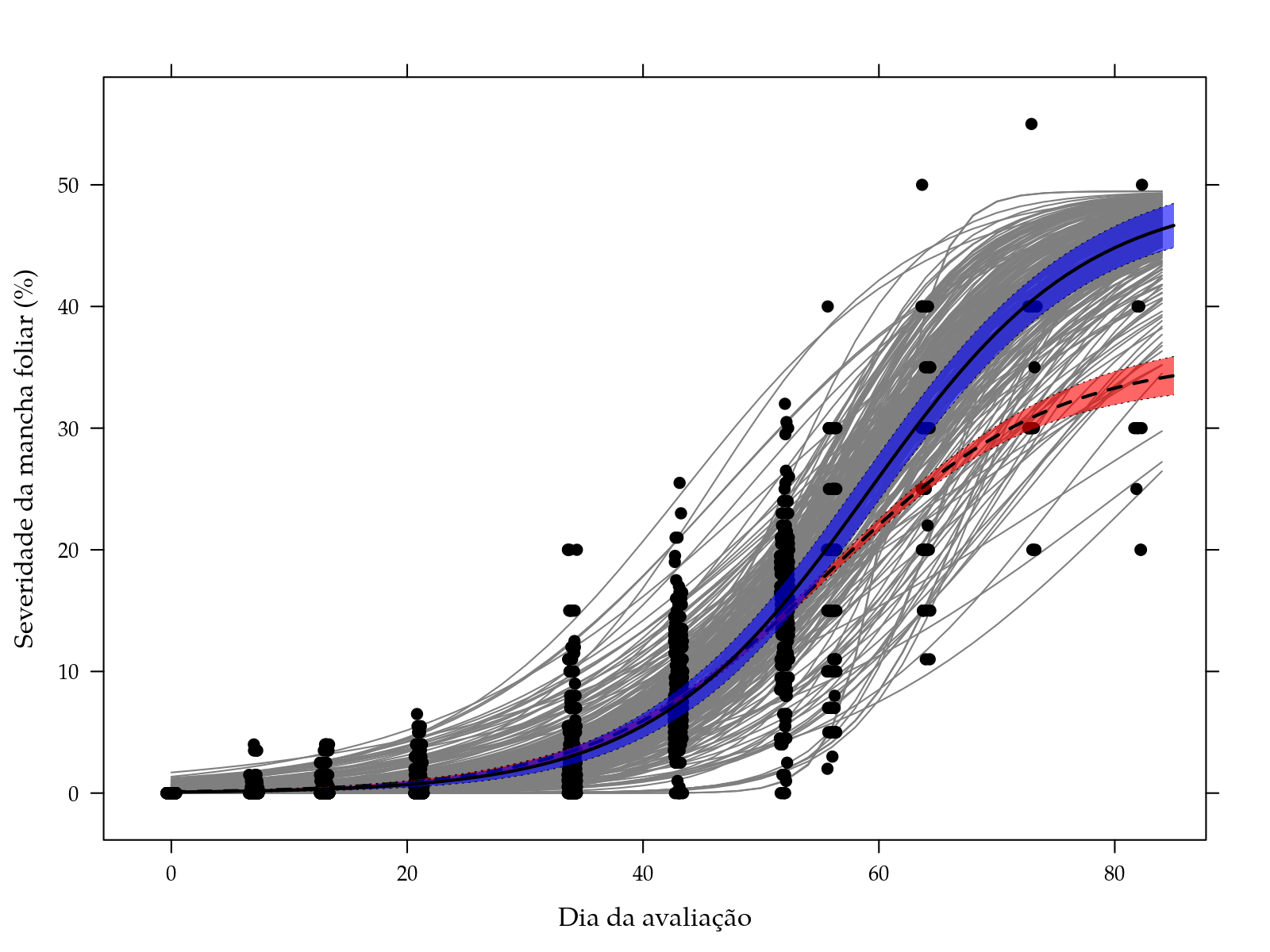
Session information
## quinta, 11 de julho de 2019, 20:05
## ----------------------------------------
## R version 3.6.1 (2019-07-05)
## Platform: x86_64-pc-linux-gnu (64-bit)
## Running under: Ubuntu 18.04.2 LTS
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.7.1
## LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.7.1
##
## locale:
## [1] LC_CTYPE=pt_BR.UTF-8 LC_NUMERIC=C
## [3] LC_TIME=pt_BR.UTF-8 LC_COLLATE=en_US.UTF-8
## [5] LC_MONETARY=pt_BR.UTF-8 LC_MESSAGES=en_US.UTF-8
## [7] LC_PAPER=pt_BR.UTF-8 LC_NAME=C
## [9] LC_ADDRESS=C LC_TELEPHONE=C
## [11] LC_MEASUREMENT=pt_BR.UTF-8 LC_IDENTIFICATION=C
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods
## [7] base
##
## other attached packages:
## [1] nlme_3.1-140 captioner_2.2.3 knitr_1.23
## [4] RDASC_0.0-6 wzRfun_0.81 rootSolve_1.7
## [7] plyr_1.8.4 latticeExtra_0.6-28 RColorBrewer_1.1-2
## [10] lattice_0.20-38
##
## loaded via a namespace (and not attached):
## [1] Rcpp_1.0.1 compiler_3.6.1 pillar_1.4.2
## [4] tools_3.6.1 digest_0.6.20 evaluate_0.14
## [7] memoise_1.1.0 tibble_2.1.3 pkgconfig_2.0.2
## [10] rlang_0.4.0 Matrix_1.2-17 commonmark_1.7
## [13] rpanel_1.1-4 yaml_2.2.0 mvtnorm_1.0-11
## [16] pkgdown_1.3.0 xfun_0.8 stringr_1.4.0
## [19] dplyr_0.8.3 roxygen2_6.1.1 xml2_1.2.0
## [22] desc_1.2.0 fs_1.3.1 rprojroot_1.3-2
## [25] grid_3.6.1 tidyselect_0.2.5 glue_1.3.1
## [28] R6_2.4.0 tcltk_3.6.1 survival_2.44-1.1
## [31] rmarkdown_1.13 multcomp_1.4-10 TH.data_1.0-10
## [34] purrr_0.3.2 magrittr_1.5 codetools_0.2-16
## [37] splines_3.6.1 backports_1.1.4 htmltools_0.3.6
## [40] MASS_7.3-51.4 assertthat_0.2.1 sandwich_2.5-1
## [43] stringi_1.4.3 doBy_4.6-2 crayon_1.3.4
## [46] zoo_1.8-6