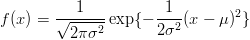
O programa R inclui funcionalidade para operações com distribuições de probabilidades. Para cada distribuição há 4 operações básicas indicadas pelas letras:
Para usar os funções deve-se combinar uma das letras acima com uma abreviatura do nome da distribuição, por exemplo para calcular probabilidades usamos: pnorm() para normal, pexp() para exponencial, pbinom() para binomial, ppois() para Poisson e assim por diante.
Vamos ver com mais detalhes algumas distribuições de probabilidades.
A funcionalidade para distribuição normal é implementada por argumentos que combinam as letras acima com o termo norm. Vamos ver alguns exemplos com a distribuição normal padrão. Por default as funções assumem a distribuição normal padrão N(μ = 0,σ2 = 1).
O primeiro valor acima corresponde ao valor da densidade da normal
A função pnorm(-1) calcula a probabilidade P(X ≤-1). O comando qnorm(0.975) calcula o valor de a tal que P(X ≤ a) = 0.975. Finalmente, o comando rnorm(10) gera uma amostra de 10 elementos da normal padrão. Note que os valores que voce obtém rodando este comando podem ser diferentes dos mostrados acima.
As funções acima possuem argumentos adicionais, para os quais valores padrão (default) foram assumidos, e que podem ser modificados. Usamos args() para ver os argumentos de uma função e help() para visualizar a documentação detalhada:
As funções relacionadas à distribuição normal possuem os argumentos mean e sd para definir média e desvio padrão da distribuição que podem ser modificados como nos exemplos a seguir. Note nestes exemplos que os argumentos podem ser passados de diferentes formas.
Para informações mais detalhadas pode-se usar help(). O comando
irá exibir em uma janela a documentação da função que pode também ser chamada com ?rnorm. Note
que ao final da documentação são apresentados exemplos que podem ser rodados pelo usuário e que
auxiliam na compreensão da funcionalidade.
Note também que as 4 funções relacionadas à distribuição normal são documentadas conjuntamente,
portanto help(rnorm), help(qnorm), help(dnorm) e help(pnorm) irão exibir a mesma
documentação.
Cálculos de probabilidades usuais, para os quais utilizávamos tabelas estatísticas podem ser facilmente obtidos como no exemplo a seguir.
Seja X uma v.a. com distribuição N(100, 100). Calcular as probabilidades:
Calcule estas probabilidades de forma usual, usando a tabela da normal. Depois compare com os resultados fornecidos pelo R. Os comandos do R para obter as probabilidades pedidas são:
Note que a última probabilidade foi calculada de duas formas diferentes, a segunda usando o argumento lower que implementa um algorítmo de cálculo de probabilidades mais estável numericamente.
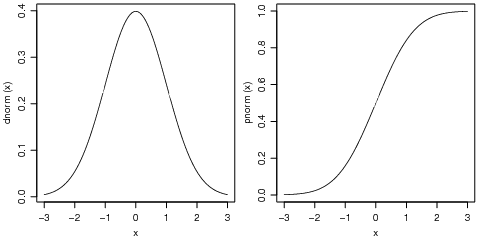
A seguir vamos ver comandos para fazer gráficos de distribuições de probabilidade. Vamos fazer gráficos de funções de densidade e de probabilidade acumulada. Estude cuidadosamente os comandos abaixo e verifique os gráficos por eles produzidos. A Figura 20 mostra gráficos da densidade (esquerda) e probabilidade acumulada (direita) da normal padrão, produzidos com os comandos a seguir. Para fazer o gráfico consideramos valores de X entre -3 e 3 que correspondem a +/- três desvios padrões da média, faixa que concentra 99,73% da massa de probabilidade da distribuição normal.
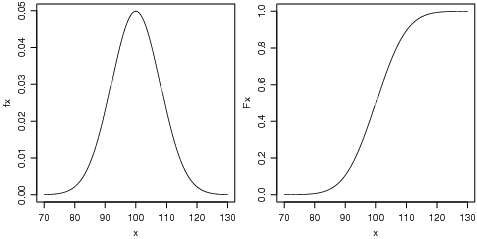
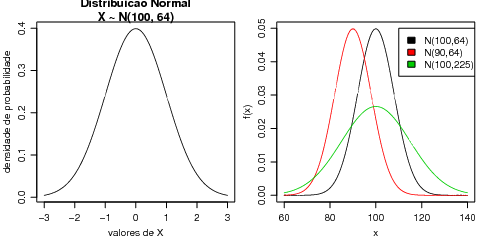
A Figura 21 mostra gráficos da densidade (esquerda) e probabilidade acumulada (direita) da N(100, 64). Para fazer estes gráficos tomamos uma sequência de valores de x entre 70 e 130 e para cada um deles calculamos o valor das funções f(x) e F(x). Depois unimos os pontos (x,f(x)) em um gráfico e (x,F(x)) no outro.
Note que, alternativamente, os mesmos gráficos poderiam ser produzidos com os comandos a seguir.
Comandos usuais do R podem ser usados para modificar a aparência dos gráficos. Por exemplo, podemos incluir títulos e mudar texto dos eixos conforme mostrado na gráfico da esquerda da Figura 22 e nos dois primeiros comandos abaixo. Os demais comandos mostram como colocar diferentes densidades em um mesmo gráfico como ilustrado à direita da mesma Figura.
Cálculos para a distribuição binomial são implementados combinando as letras básicas vistas acima com o termo binom. Vamos primeiro investigar argumentos e documentação com args() e dbinom().
Seja X uma v.a. com distribuição Binomial com n = 10 e p = 0.35. Vamos ver os comandos do R para:
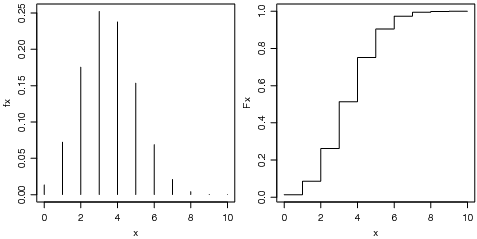
Note que sendo uma distribuição discreta de probabilidades os gráficos são diferentes dos obtidos para distribuição normal e os cálculos de probabilidades devem considerar as probabilidades nos pontos. Os gráficos das funções de densidade e probabilidade são mostrados na Figura 23.
As probabilidades pedidas são obtidas com os comandos a seguir.
Para a distribuição uniforme contínua usa-se as funções *unif() onde * deve ser p, q, d ou r como mencionado anteriormente. Nos comandos a seguir inspecionamos os argumentos, sorteamos 5 valores da U(0, 1) e calculamos a probabilidade acumulada até 0,75.
Portanto, o default é uma distribuição uniforme no intervalo [0, 1] e os argumentos opcionais são min e max. Por exemplo, para simular 5 valores de X ~ U(5, 20) usamos:
Não há entre as funções básicas do R uma função específica para a distribuição uniforme discreta com opções de prefixos r,d,p e d, provavelmente devido a sua simplicidade, embora algumas outras funções possam ser usadas. Por exemplo para sortear números pode-se usar sample(), como no exemplo a seguir onde são sorteados 15 valores de uma uniforma discreta com valores (inteiros) entre 1 e 10 (X ~ Ud(1, 10)).
A função sample() não é restrita à distribuição uniforme discreta, podendo ser usada para sorteios, com ou sem reposição (argumento replace, default sem reposição), com a possibilidade de associar diferentes probabilidades a cada elemento (argumento prob, default probabilidades iguais para os elementos).
Vejamos alguns exemplos:
Este último exemplo ilustra ainda que os valores passados para o argumento prob não precisam ser probabilidades, são apenas entendidos como pesos. A própria função trata isto internamente fazendo a ponderação adequada.
Nos exercícios abaixo iremos também usar o R como uma calculadora estatística para resolver alguns exemplos/exercícios de probabilidade tipicamente apresentados em um curso de estatística básica.
Os exercícios abaixo com indicação de página foram retirados de:
Magalhães, M.N. & Lima, A.C.P. (2001) Noções de Probabilidade e Estatística. 3 ed. São
Paulo, IME-USP. 392p.
| Paciente | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| Incidência | 2 | 5 | 0 | 2 | 1 | 5 | 3 | 3 | 3 | 2 | 0 | 1 | 1 |
| Paciente | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| Incidência | 4 | 5 | 2 | 2 | 3 | 2 | 1 | 5 | 4 | 0 | 0 | 3 | 3 |
Estudos anteriores assumem que a incidência de câncer em parentes próximos pode ser modelada pela seguinte função discreta de probabilidades:
| Incidência | 0 | 1 | 2 | 3 | 4 | 5 |
| pi | 0.1 | 0.1 | 0.3 | 0.3 | 0.1 | 0.1 |
| Resistência | 2 | 3 | 4 | 5 | 6 |
| pi | 0,1 | 0,1 | 0,4 | 0,2 | 0,2 |
Simule a resistência de 5000 vigas a partir de valores gerados de uma uniforme [0,1]. (Dica: Use o comando ifelse() do R). Verifique o histograma.