Seguinte: Teste de Kruskal-Wallis Acima: Comparando mais do que Anterior: Comparando mais do que
Vimos que para dados contínuos, gráficos do tipo boxplot são em geral úteis para auxiliar nas comparações entre medidas em dois grupos. Eles são tão apropriados aqui, senão mais ainda, para comparar mais do que dois grupos de dados contínuos.
Por exemplo, a seguir é apresentado um boxplot de peso ao nascer por raça:
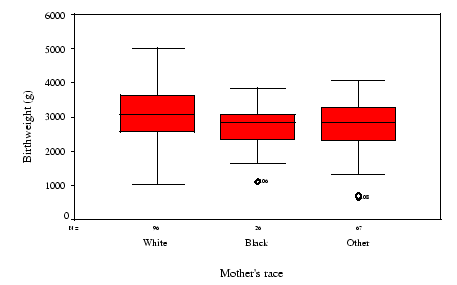
Neste caso, como os boxplots apresentam uma grande interseção, é difícil de se avaliar de existe uma diferença real entre grupos, embora pareça que se existe uma diferença real então é provável que ela seja pequena.
Uma consequência disto é que pode ser difícil ver pequenas diferenças em médias somente olhando nos boxplots.
Se um boxplot não mostrar diferenças notáveis entre grupos, então uma boa idéia é criar intervalos de confiança separados para as médias de cada um dos grupos e colocá-los juntos num gráfico. A sobreposição ou não destes intervalos de confiança trará novas informações sobre a diferença ou não das médias dos grupos sem que seja necessário executar quaisquer testes formais.
Voltando aos dados de peso ao nascer novamente, podemos obter um gráfico mostrando intervalos de confiança de 95% para as médias de bebês nascidos de mães de diferentes raças.
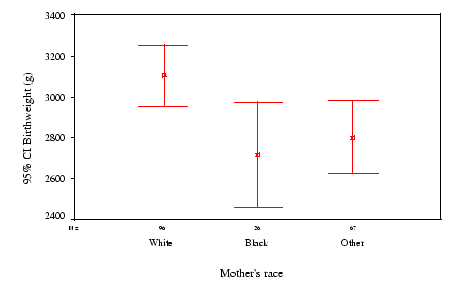
O intervalo de confiança para a média para mães brancas quase não se sobrepõe com os outros, e parece que bebês de mães brancas tendem a ser mais pesados em média.
Contudo, este gráfico não mostra diferenças muito claras entre mães negras e outras mães.
Se as diferenças forem de significância prática, podemos agora nos perguntar por que estas diferenças podem existir, por exemplo, diferenças podem ser explicadas por comportamentos de fumo, idade, pesos, etc, diferenciados das mulheres nos três grupos.
Note que o gráfico das médias acima só é apropriado em situações em que é razoável calcular uma média e onde os supostos para a construção de intervalos de confiança são válidos (a distribuição não é muito distante de uma normal e/ou o tamanho de amostra é grande).
Lembre que para se avaliar a diferença entre duas médias, foi feito um teste-t para duas amostras. Para múltiplas amostras, usaremos uma análise de variância (ANOVA).
Nas situações em que os dados são escores de algum tipo, ou contagens com vários valores próximos de zero, boxplots podem ainda ser úteis, mas o gráfico com os intervalos de confiança já não serão apropriados.
Por exemplo, os seguintes dados são o número de orquídeas encontradas em quadrats alocados aleatóriamente em 4 locais: A, B, C, D.

O interesse é verificar se o número de orquídeas tendem a diferir de um local para outro.
Quando existem somente contagens pequenas nos dados, ao invés do boxplot, um gráfico de pontos pode ser mais apropriado.
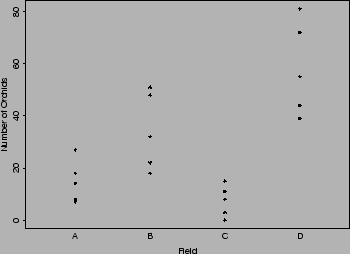
Quando tinhamos duas amostras deste tipo elas eram comparadas usando o teste U de Mann-Whitney. Para mais do que duas amostras, usamos um teste não paramétrico similar chamado de teste de Kruskal Wallis.
Quando os dados são categóricos, frequentemente uma simples tabela é a melhor forma de comparar grupos, possivelmente com percentuais calculados para auxiliar as comparações.
Embora os dados originais possam ser númericos, algumas vezes, especialmente com dados de contagem ou escores, ou onde existem uma grande quantidade de empates, pode ser mais apropriado colapsar os dados em categorias.
Por exemplo, para comparar o comportameno de fumo de diferentes grupos de pessoas, podemos perguntar a cada pessoa quantos cigarros ela fuma por dia, e então para propósito de análise, converter esta informação em uma variável com categorias não fuma, fuma pouco, fuma moderadamente, fuma muito. (É importante fazer definições destas categorias explicitamente, ou seja, fuma pouco poderia ser definido como entre 1 e 10 cigarros.
Podemos também colapsar dados em categorias por outras razões. Por exemplo, podemos querer comparar diferentes grupos de idade de forma que possamos calcular o percentual de bebês com baixo peso ao nascer em cada grupo. Isto pode ser mais informativo do que um gráfico de peso ao nascer versus idade.

Silvia Shimakura 2005-11-08