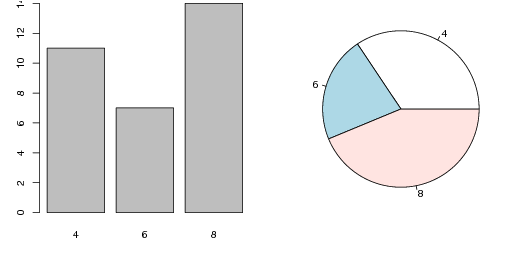|
|
Nesta sessão vamos ver alguns (mas não todos!) comandos do R para fazer uma análise descritiva de um conjunto de dados.
Uma boa forma de iniciar uma análise descritiva adequada é verificar os tipode de variáveis disponíveis. Variáveis podem ser classificadas da seguinte forma:
e podem ser resumidas por tabelas, gráficos e/ou medidas.
Vamos ilustrar estes conceitos com um conjunto de dados já incluído no R, o conjunto mtcars que descreve características de diferentes modelos de automóvel.
Primeiro vamos carregar e inspecionar os dados. Os comandos abaixo mostram como: (i) carregar os dados, (ii) visualizar todo o conjunto de dados, (iii) obter informações sobre os dados. Sendo este um conjunto de dados que vem junto com o R ele possui documentação que explica os dados. O mesmo acontece com todos os conjuntos de dados distribuídos com o R.
Digitando mtcars foi possível visualizar todos os dados. Entretanto em geral não queremos visualizar todos os dados, mas apenas uma parte deles. Os dois primeiros comandos abaixo mostram apenas a parte inicial do arquivo de dados. Os demais comandos mostram como verificar a dimensão do conjunto de dados (número de linhas e colunas) e como ver o nome das variáveis.
Vamos agora, por simplicidade, selecionar um subconjunto destes dados com apenas algumas das variáveis. Para isto vamos criar um objeto chamado mtc que contém apenas as variáveis desejadas. Para selecioná-las indicamos os números das colunas correspondentes à estas variáveis.
Vamos anexar o objeto para facilitar a digitação com o comando abaixo. O uso e sentido deste comando será explicado mais adiante.
NOTA: em versões mais recentes do R foi introduzido a função with() que dispensa o uso de attach(), além de ser mais segura.
Vamos agora ver uma descrição da variável número de cilindros. Vamos fazer uma tabela de frequências absolutas e gráficos de barras e de setores.
|
|
Para obter frequências relativas poderíamos usar os comandos abaixo. Note duas formas alternativas.
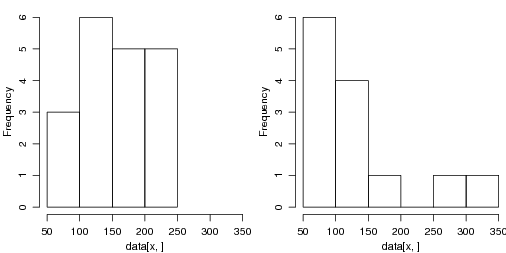
Passando agora para uma variável quantitativa contínua vamos ver o comportamento da variável que mede o rendimento dos carros (em mpg – milhas por galão). Primeiro fazemos uma tabela de frequências, depois gráficos (histograma, box-plot e diagrama ramos-e-folhas) e finalmente obtemos algumas medidas que resumem os dados.
Vamos primeiro ver o resumo de duas variáveis categóricas: o tipo de marcha e o número de cilindros. Os comandos abaixo mostram como obter a tabela com o cruzamento destas variáveis e gráficos. Note e compare as saídas obtidas com cada um dos comandos a seguir.
É possível também obter visualizações gráficas destes cruzamentos. Experimente os comandosa seguir, explore seus argumentos e observe os gráficos produzidos.
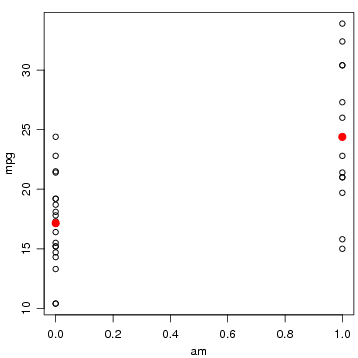
Agora vamos relacionar uma categórica (tipo de câmbio) com uma contínua (rendimento). O primeiro comando mostra como obter medidas resumo do rendimento para cada tipo de câmbio. A seguir obtemos as médias para cada tipo de câmbio de duas formas diferentes, a primeira selecionando os dados de cada um individualmente, e a segunda obtendo ambas as médias de uma só vez.
A seguir são mostrados dois tipos de gráficos que podem ser obtidos para descrever o comportamento e associação destas variáveis.
|
|
Pode-se fazer um teste estatístico usando o teste t para comparar os redimentos de carros com diferentes tipos de câmbio e/ou com diferentes números de cilindros usando a análise de variância.
Inspecione ainda o gráfico produzido pleo comando abaixo.
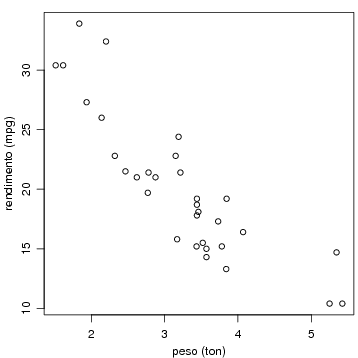
Passamos agora para a relação entre duas variáveis contínuas (peso e rendimento) cuja relação pode ser investigada como se segue. O coeficiente de correlação linear de Pearson pode ser obtido com:
e o gráfico de rendimento versus peso com
Podemos ainda usar recusos gráficos para visualizar três variáveis ao mesmo tempo. Inspecione os gráficos produzidos com os comandos a seguir.
Vamos agora utilizar um outro conjunto de dados que já vem disponível com o R – o conjunto airquality.
Estes dados são medidas de: concentração de ozônio (Ozone), radiação solar (Solar.R), velocidade de vento (Wind) e temperatura (Temp) coletados diariamente (Day) por cinco meses (Month).
Primeiramente vamos carregar e visualisar os dados com os comandos:
> data(airquality) # carrega os dados
> airquality # mostra os dados |
Vamos agora usar alguns comandos para “conhecer melhor” a estrutura dos dados. Nos comandos a seguir verificamos queairquality é um data-frame, obtemos os nomes das variáveis (colunas), a dimensão.
Note ainda que o comando help(airquality) mostra a documentação destes deados, disponível por se tratar de um conjunto de dados já incluido no R. Bem, agora que conhecemos melhor o conjunto airquality, sabemos o número de dados, seu formato, o número de nome das variáveis podemos começar a analisá-los.
Veja por exemplo alguns comandos:
> summary(airquality) # rápido sumário das variáveis
> summary(airquality[,1:4]) # rápido sumário apenas das 4 primeiras variáveis > mean(airquality$Temp) # média das temperaturas no período > mean(airquality$Ozone) # média do Ozone no período - note a resposta NA > airquality$Ozone # a razão é que existem ‘‘dados perdidos'' na variável Ozone > mean(airquality$Ozone, na.rm=T) # média do Ozone no período - retirando valores perdidos |
Note que os útimos três comandos são trabalhosos de serem digitados pois temos que digitar
airquality a cada vez!
Mas há um mecanismo no R para facilitar isto: o caminho de procura (“search path”). Começe digitando e
vendo s saída de:
search()
O programa vai mostrar o caminho de procura dos objetos. Ou seja, quando voce usa um nome do objeto o R vai procurar este objeto nos caminhos indicado, na ordem apresentada.
Pois bem, podemos “adicionar” um novo local neste caminho de procura e este novo local pode ser o nosso objeto airquality. Digite o seguinte e compare com o anterior:
> attach(airquality) # anexando o objeto airquality no caminho de procura.
> search() # mostra o caminho agora com o airquality incluído > mean(Temp) # e ... a digitação fica mais fácil e rápida !!!! > mean(Ozone, na.rm=T) # pois com o airquality anexado o R acha as variáveis |
NOTA: Para retirar o objeto do caminho de procura basta digitar detach(airquality).
Bem, agora é com voce!
Reflita sobre os dados e use seus conhecimentos de estatística para fazer uma análise
descritiva interessante destes dados.
Pense em questões relevantes e veja como usar medidas e gráficos para respondê-las. Use os comandos mostrados anteriormente. Por exemplo:
Há vários conjuntos de dados incluídos no programa R como, por exemplo, o conjunto mtcars. Estes conjuntos são todos documentados, isto é, voce pode usar a função help para obter uma descrição dos dados. Para ver a lista de conjuntos de dados disponíveis digite data(). Por exemplo tente os seguintes comandos: