Resposta:
Resposta:
| reação | Feminino | Masculino
| |||
| alérgica | Dosagem Baixa | Dosagem Alta | Dosagem Baixa | Dosagem Alta | |
| Leve | 21 | 15 | 22 | 34 | |
| Moderada | 49 | 12 | 14 | 29 | |
| Forte | 28 | 35 | 17 | 11 | |
As dados foram digitados no R com o seguinte comando:
Responda as seguintes perguntas e nos ítens onde são mostrados comandos do R explique com palavras o que está sendo calculado e forneça a resposta.
- quais as variáveis e quais os níveis das variáveis envolvidas no problema?
- qual variável está associada a cada uma das dimensões do array?
- apply(ar,2,sum)
- apply(ar,3,sum)/sum(ar)
- apply(ar, c(3,2), sum)/apply(ar,3,sum)
Resposta:
> dimnames(ar) <- list(c("Baixa", "Alta"), c("Leve", "Moderada", "Forte"), c("Feminino",
+ "Masculino"))
> apply(ar, 2, sum)
-
Variável reaçâo: níveis: leve, moderada, forte
Variável dosagem: níveis: baixa, alta
Variável sexo: níveis: feminino, masculino - dimensão 1: variável dosagem, dimensão 2: variável reação, dimensão 3: variável sexo.
- totais de indivíduos com cada tipo de reação alérgica
- proporções de pessoas de cada sexo dentre todos os pacientes
- proporções de cada reação alérgica dentro de cada um dos sexos
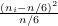 que sabe-se ter distribuição assintótica Chi-Quadrado com 5 graus de liberdade. Mostre como
obter o valor para testar ao nível de α = 0.05 a hipótese de que todos os números ocorrem com a mesma frequência.
Finalmente, numa terceira fase, deseja-se ilustrar computacionalmente o fato da estatística ter esta distribuição assintótica.
Mostre como isto poderia ser feito, incluindo comandos para visualização gráfica dos resultados. Nas três fases deste problema
explique com palavras os passos de cada procedimento e mostre o código R necessário para implementar estes
passos.
que sabe-se ter distribuição assintótica Chi-Quadrado com 5 graus de liberdade. Mostre como
obter o valor para testar ao nível de α = 0.05 a hipótese de que todos os números ocorrem com a mesma frequência.
Finalmente, numa terceira fase, deseja-se ilustrar computacionalmente o fato da estatística ter esta distribuição assintótica.
Mostre como isto poderia ser feito, incluindo comandos para visualização gráfica dos resultados. Nas três fases deste problema
explique com palavras os passos de cada procedimento e mostre o código R necessário para implementar estes
passos.
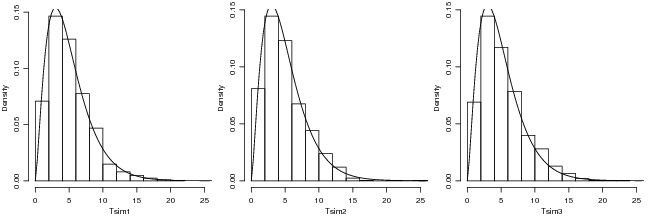
- vamos adotar (arbitrariamente) N = 10000 lançamentos e verificar se as frequências observadas são semelhantes
- Calcula-se a estatística e o valor crítico de acordo com a distribuição χ2. Alternativamente poderia-se usar a função chisq.text().
- Agora vamos fazer 1000 amostras para o lancamento da moeda 100, 1000 e 10000 vezes e comparar a distribuição da
estatística obtida poir simulação com a distribuição χ2.
> Tfc <- function(tab, size) sum(((tab - (size/6))^2)/(size/6))
> sim1 <- sapply(1:1000, function(...) {
+ table(sample(1:6, 100, rep = T))
+ })
> Tsim1 <- apply(sim1, 2, Tfc, size = 100)
> sim2 <- sapply(1:1000, function(...) {
+ table(sample(1:6, 1000, rep = T))
+ })
> Tsim2 <- apply(sim2, 2, Tfc, size = 1000)
> sim3 <- sapply(1:1000, function(...) {
+ table(sample(1:6, 10000, rep = T))
+ })
> Tsim3 <- apply(sim3, 2, Tfc, size = 10000)
> fc <- function(x) dchisq(x, df = 5)
> hist(Tsim1, main = "", prob = T, xlim = c(0, 25))
> curve(fc, 0, 30, add = T)
> hist(Tsim2, main = "", prob = T, xlim = c(0, 25))
> curve(fc, 0, 30, add = T)
> hist(Tsim3, main = "", prob = T, xlim = c(0, 25))
> curve(fc, 0, 30, add = T)